Player2Vec by pass - нейросетевая модель векторизации игроков

Недавно я посмотрел последний форум OptaPro и открыл для себя новый футбольный мир на стыке двух сфер, которым я уделяю большую часть своего времени. Особенно меня заинтересовала презентация Бенджамина Товарни «Player2Vec», в которой он использовал все действия футболистов для составления персонализированного вектора. В этом посте будет описана примерная реализация упрощенной версии его модели, учитывающей только данные по пасам.
В своей версии я использовал открытые данные по Чемпионату Мира 2018 от StatsBomb. Также, для упрощения я использовал только данные по пасам, а конкретно: координаты начала, координаты конца, длина, высота и угол паса. Для реализации модели я использовал нейросетевую архитектуру, похожую на Word2Vec. Главный недостаток презентации Товарни - это то, что он уделил только один слайд для объяснения модели (спойлер: восстановить ее или понять как она работает по этому слайду практически невозможно). Вся остальная презентация была посвящена анализу результатов и их визуализации. Я же попытаюсь наоборот сделать уклон в то, как работает модель, причем также постараюсь минимально затрагивать вещи, касающиеся глубокого обучения, чтобы всем было понятно. Тренировался объяснять на девушке, она учится на психолога, и, вроде, у меня получилось.
Немного о Word2vec
Для начала имеет смысл сказать о том, что такое word2vec. Это очень известная в nlp кругах архитектура от гугла, состаящая из двух слоёв. Суть ее в том, что на выходе получаются контекстные вектора слов, то есть на вход подаются все возможные пары слов из предложения и модель учится эти слова соотносить, получается усложнённый набор вероятностей встретиться с каким-то словом в предложении.
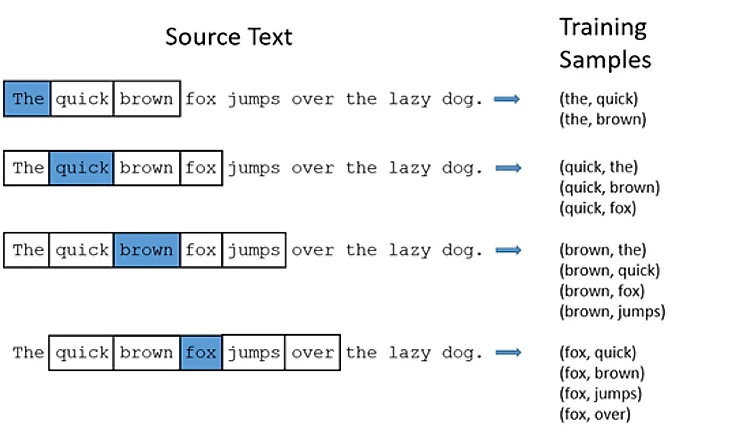
В пасовой модели используется похожая схема (опять упрощенная, но что поделать). Разница в первом слое и составлении датасета. В word2vec наличие двух слоев в первую очередь обусловлено тем, что есть не только вероятность попадания слова a в контекст слова b, но и наоборот. Здесь же нужно обучить модель соотносить вектор паса (его фичи, перечисленные выше) с игроком, отдавшим этот пас. Поэтому фактически нам хватит и одного слоя, но количество фич, описывающих пас - сильно меньше количества игроков в датасете. Поэтому я добавил первый слой, который делает этот переход более плавным и задаёт размерность нашему будущему вектору игрока (hidden layer).
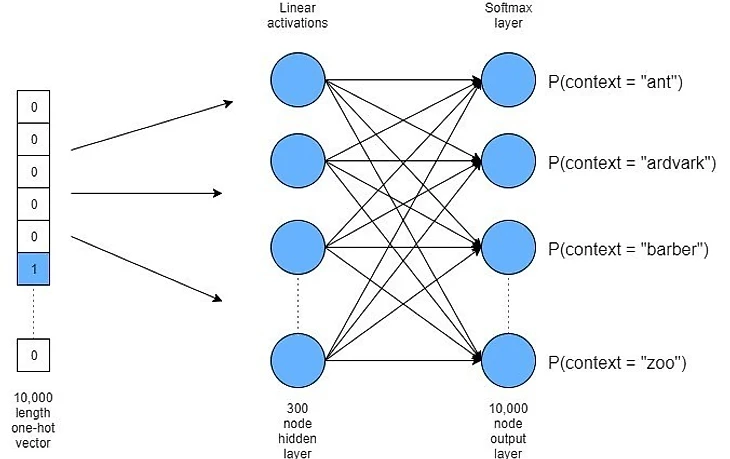
Небольшой экскурс в нейронные сети
Слой в этой терминологии означает матрицу с числами, описывающими переходы между нейронами, обучение сети заключается в «умном» подборе этих чисел. Изначально слои заполняются рандомно, но корректируются по ходу обучения.
Получение векторов из модели
Зная это можно двигаться дальше. После обучения нас будет интересовать только последний слой, который по сути, является большой матрицей размерности (hidden_dim, vocab_size), где vocab_size - это количество футболистов в датасете (на самом деле все чуть сложнее - из-за слишком маленького объема данных приходится убирать пассажиров - игроков, отдавших слишком мало передач, поэтому vocab_size немного меньше, чем общее количество игроков). Остаётся последний вопрос: как получить вектор для каждого футболиста из этой матрицы? С этим нам поможет логика работы созданной нейронной сети. Так как она соотносит пас с конкретным игроком, то очевидно, что у каждого футболиста есть свой «порядковый номер» в нашем датасете (этот порядковый номер вместе с с вектором паса мы и передаём модели при обучении). Получается, что вектор i-го игрока - это i-ая «строка» той самой матрицы, где i - это порядковый номер игрока. И да, длина каждого вектора будет равна hidden_dim.
Визуализация результатов обучения
Можете выдохнуть - далее не будет никаких объяснений (почти), только визуализация результатов и оправдания.
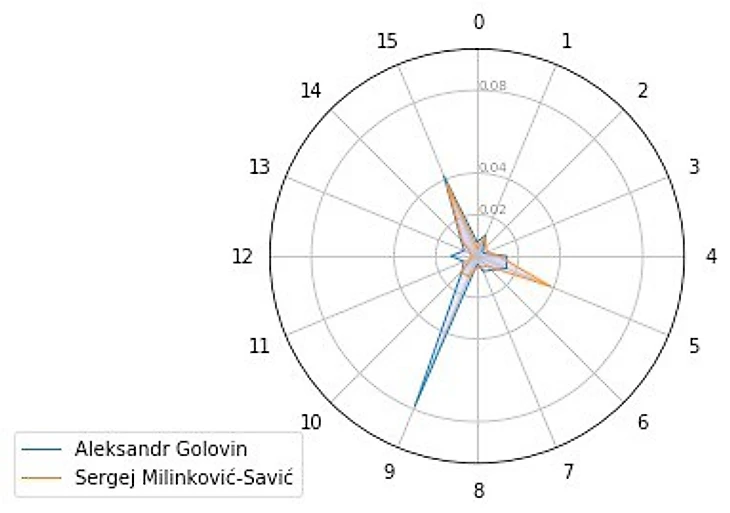
Вот, например визуализация векторов Головина и Милинковича-Савича. Важный момент - эти вектора учитывают только стиль игры в пас.
Однако, это сравнение не очень показательно. Намного интереснее посмотреть топ-5 ближайших игроков к кому-нибудь. Делается это с помощью Евклидова расстояния (или косинусного, но тогда нужно все вектора нормализовать).

Вот уже намного более показательное применение, показывающее ближайших игроков для Пике (обратите внимание на скачок в расстоянии между Рамосом и Карвальо, потому что последний - разыгрывающий опорник, а защитники перед ним отличаются хорошим продвижением и играют за сборные, которые много владеют мячом. Также, вероятно, Карвальо часто опускался к защитникам для оказания помощи в билдапе).
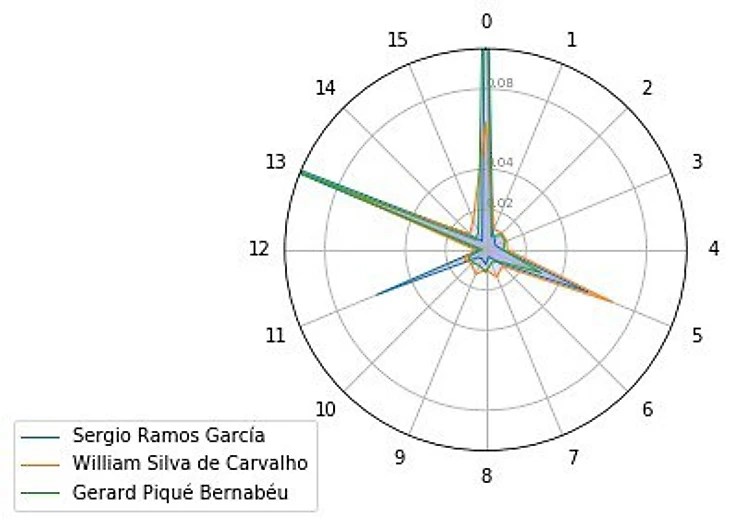
На картинке не идеально видно, но можно заметить, что радар Карвальо имеет более короткие «ветки», но их значительно больше, что даёт его радару большую плотность (вероятно, так нейросеть показала его большую вариативность как разыгрывающего опорника).
Что дальше? Почему бы не составить вектора команд, взяв среднее арифметическое по игрокам этой команды? Так и сделаем и посмотрим «ближайших соседей» для России и Испании. А затем, с помощью PCA изобразим все команды на графике, приблизительно отражающем их близость по стилю игры с мячом:


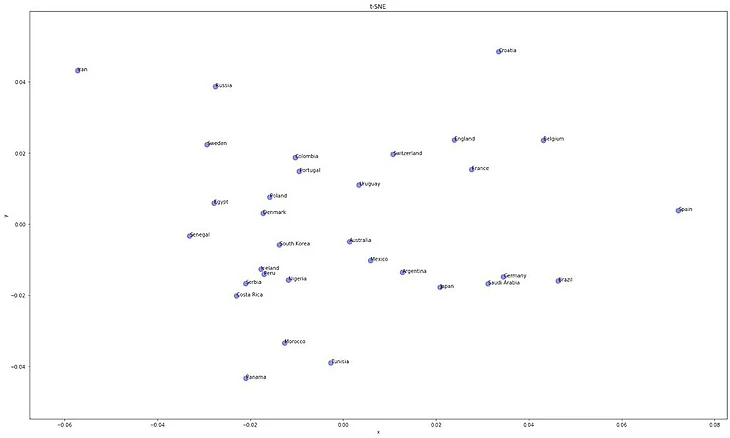
В целом, по-моему, векторизация более, чем удачная. Однако у здорового человека, скорее всего, возникнут вопросы по поводу близости Саудовской Аравии к Испании. Ответом будет, что модель показывает, по сути, стиль команды, а Саудовская Аравия пыталась играть в красивый футбол, основанный на владении (о чем даже говорил наш гуру Вадим Лукомский), но дело в том, что у неё это достаточно плохо выходило (как и у Германии, к которой она ещё ближе, чем к Испании). Также, можно заметить, что на графике правее находятся команды, больше владеющие мячом. И если выделение Испании с Ираном вполне очевидно, то было бы интересно исследовать отдаление Хорватии от остальных. Однако, для серьёзных исследований нужно в любом случае обучить модель на большем объёме данных.
Использование и перспективы
Вариантов использования достаточно и они все хорошо освящены в оригинальной презентации, ссылку на которую я указал в начале статьи. Из основного: скаутинг, анализ соперника и тд. Естественно, такого рода модели не заменят аналитиков, но они сильно упростят им работу и помогут экономить время, что очень важно в условиях еженедельных матчей.
Для тех, кого это может заинтересовать, выкладываю ссылку на GitHub репозиторий с кодом, более полной визуализацией и обученной моделью. Также, если есть вопросы по поводу работы модели, постараюсь ответить на них по почте daniel@zholkovsky.com
Даниэль Жолковский



Если искать что-то похожее, то в своей работе по созданию пространства футболистами Luke bornn (не помню название статьи, если интересно, то найду) построил «вспомогательную» модель, которая «размечает» пространство по тому, насколько сложно продвинуть мяч в точку этого пространства относительно расположения игроков и мяча. Думаю, что на основе этой модели можно попробовать построить что-то похожее. Хотя изначально речь в dvoa о другом)