Цифровой скаутинг

Цифровой скаутинг
От фильтров по параметрам до машинного обучения. Краткий обзор истории, технологий, возможностей.

Предположим мы хотим посмотреть какие есть интересные игроки в некотором чемпионате(чемпионатах) который мы до сих пор не видели ни разу. Тут два пути.
Можно сесть и начать смотреть все матчи.
Можно отфильтровать игроков по статистикам, составить лонг лист и смотреть только матчи/эпизоды с их участием.
Первый путь - это чисто видео скаутинг. Второй путь - это видео-цифровой. Цифровая часть здесь отвечает за составление лонг листа, а конечное впечатление формируется после изучения видео.
Надо добавить что если вы уже смотрели все матчи данного чемпионата то цифровой скаутинг особо и не нужен.
Фильтрация по статистикам
Эта функция встроена в любом провайдере статистик. Например мы хотим выбрать лучших атакующих игроков прошлого сезона по таким характеристикам как ожидаемые голы и ожидаемые ассисты. Зашли в Wyscout или Instat и выбрали xA > a, xG > b. На выходе мы получим подмножество игроков, которое будет выглядеть как показано на следующем рисунке.

Здесь, две линии xA = a и xG = b делят все наше пространство игроков на четыре квадранта. В первом будет прошедшие фильтрацию. Остальные три отсеиваются.
В реальной жизни мы можем фильтровать не по двум параметрам. Их может быть 5-10. Но для наглядности останемся в 2D.
Надо также отметить, что для игроков разных позиций будут очевидно разные фильтры. И если для нападающих все попроще - за них прежде всего говорят их голы, то с игроками других амплуа сложнее и не всегда очевидно какие параметры стоит учитывать.
Вернемся к предыдущему графику. Очевидно, что на нем отсеиваются и лучшие бомбардиры (квадрант 2), и лучшие ассистенты (квадрант 4). Остаются игроки в основном средние. Причем если мы захотим настроить наши фильтры изменяя значения a и b т.е. двигая разделяющие линии, мы неизбежно зачерпнём из квадранта 3, где как раз сосредоточены игроки представляющие наименьший интерес.
Таким образом, использовать фильтрацию по фильтрам вида xA > a, xG > b… особенно на больших данных не очень целесообразно. Фильтры можно использовать для очень грубого отсева и дополняя их такими графиками как наверху можно получать некое представление исследуемом множестве футболистов. Однако график отражает соотношение только 2-3 параметров что не дает сформировать целостное представление о качестве игроков.
Тем более, что можно сделать лучше.
Линейный рейтинг
Тимофей Ушанский в своей статье описывает метод ранжирования игроков, в основе которого подсчет суммы K1*X1 + K2*X … KN*XN. Где K - коэффициенты, X - некоторые статистики игроков. Частным случаем этой формулы является просто сумма параметров. Если выставить условие xA + xG > c то визуально наше разбиение будет выглядеть как показано на следующем рисунке.

Это уже гораздо лучше и интереснее. Мы дополняем наше множество лучшими бомбардирами и ассистентами и не добавляем никого лишнего. Мы можем меняя величину c в уравнении двигать разделяющую линию ближе-дальше от начала координат. Изменяя коэффициенты K можно менять угол ее наклона, например больше в сторону ассистентов или больше в сторону бомбардиров. Еще замечательный плюс: мы видим насколько далеко каждый игрок от границы, и легко можно посчитать расстояние. Наиболее удаленные игроки будут представлять наибольший интерес, и наоборот. Так мы получаем свой рейтинг игроков, по которому можно их отсортировать, чего нельзя сделать просто фильтрами.
Имея рейтинг можно не просто просматривать всех отобранных игроков подряд, но в определенной последовательности. Более того сама необходимость отсева отпадает, имея рейтинг можно рассмотреть первых 5 или 10 или 50 игроков, по мере необходимости.
Да, в Инстате есть встроенный индекс, но он не является прямым отражением статистик игрока. Он во-первых кумулятивен - учитывает историю выступлений, во-вторых нормируется по силе чемпионата. Так что, если он не совсем отражает ваши потребности, то может быть полезно сделать свой рейтинг, просто посчитав K1*X1 + K2*X … KN*XN.
Это придется делать, скорее всего, своими руками, так как большинство интерфейсов от провайдеров статистики такими функциями не обладает, известным мне исключением является xglab.pro. Но имея Excel все это возможно сделать самому.
Однако, зададимся вопросом: какие должны быть коэффициенты К1, К2… ? На данный момент, общепринятая практика выставить их на глаз. Кто как считает, тот так и выставляет. Для ЦЗ важно количество перехватов? Поставим коэффициент побольше. Количество голов со стандартов? Чуть поменьше.
Насколько я понимаю это сейчас наиболее распространенная практика везде, где используется цифровой скаутинг.
Но раз уж мы с вами любим цифры, то можно сделать следующий шаг. Подобрать веса параметров не на глаз, а объективными методами.
Машинное обучение
Логичным решением проблемы подбора коэффициентов является использование автоматического подбора оптимальных значений, иначе говоря алгоритма линейной регрессии.
Как это работает?
Предположим у нас уже есть некоторое множество игроков, где про каждого мы знаем должен он находится выше разделительной линии или ниже. Тогда провести линию, разделяющую эти два класса, остается делом техники. Это и делает машинное обучение. Проводит линию которая бы наиболее удачно отделяла "синих" от "красных" и дает ее коэффициенты.

Где же взять это обучающее множество?
Wyscout дает данные за последние 4 сезона, что позволяет отследить прогресс игроков во времени. Можно посмотреть на игроков игравших в некотором чемпионате (за пределами топ 5) и отметить перешел он в более сильную лигу или нет.
Нашим допущением будет, что если игрок перешел в более сильную лигу, значит он своей игрой выделялся, и статистики это отражают. Таким образом перешедшие будут "синими" не перешедшие "красными". Понятно что такое разбиение не является однозначно точным, но нам и не нужна большая точность. За счет большого количества данных влияние отдельных ошибок устраняется.
Таким образом на старых данных 3-4 летней давности можно получить наши коэффициенты. Эти коэффициенты будут более объективно отражать вес каждого параметра игрока в его оценке, чем взятые из головы.
Что дальше?
Я немного обрисовал, как машинное обучение может быть применено для подбора коэффициентов для ранжирования игроков на основе линейной функции.
Однако это лишь часть его возможностей.
Например как осуществить сам выбор набора параметров для каждой позиции? Нужно ли рассматривать одновременно xG и забитые голы или достаточно чего-то одного, или же вообще лучше взять количество ударов в створ?
Подбор значимых параметров это тоже задача машинного обучения.
Кроме того как распределить игроков по ролям? Да, можно воспользоваться определениями от провайдера, но они бывают весьма размыты. Алексей Миранчук, например, определяется как: AM, RW, CF. Но каждая из этих ролей имеет разные наборы весов для статистик. Кластеризация - это алгоритм машинного обучения, который поможет автоматически определить роли игроков исходя из их статистик.

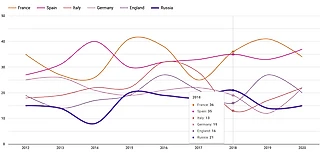
Приведенный рисунок взят из исследования CIES.
К тому же машинное обучение не ограничивается линейными моделями. Нелинейные модели могут давать более качественный результат.
Заключение
Высокие технологии не спеша, но уверенно проникают в спорт и в частности в футбольный скаутинг. Пока что, в основном, они применяются самими провайдерами данных. Но наиболее амбициозные клубы начинают вести собственную исследовательскую работу в этом направлении. Поиск по параметрам уходит в прошлое, так же как ушли в прошлое кассеты VHS.