Аналитика в футболе: обзор ситуации

Аналитика давно неотъемлемая часть спорта. От англичанина, считавшего количество передач, сидя на трибуне и Билла Джеймса, человека который действительно изменил всё (а не Брэд Питт), до современных гиков из Йелей, которые лучше Леброна знают куда ему нужно бежать и откуда бросать. Лавинообразное развитие технологий в последнее время приводит к тому, что нужно очень быстро бежать вперёд, чтобы оставаться на месте. Железо и ПО позволяют сейчас считать тысячи статистик, снимать сотни показателей, рисовать траектории движения по видеокартинке и т.д.
При этом складывается ощущение, что футбол находится немного в отстающих. Возможно мне так кажется из-за бОльшего погружения в североамериканские лиги (НФЛ, НБА, МЛБ) где считается всё. Возможно, европейский футбол более закрыт в плане распространения информации. Отчёт о состоянии футбольной аналитики от компании Left Field, о котором далее пойдёт речь, как раз призван закрыть информационную пустоту.
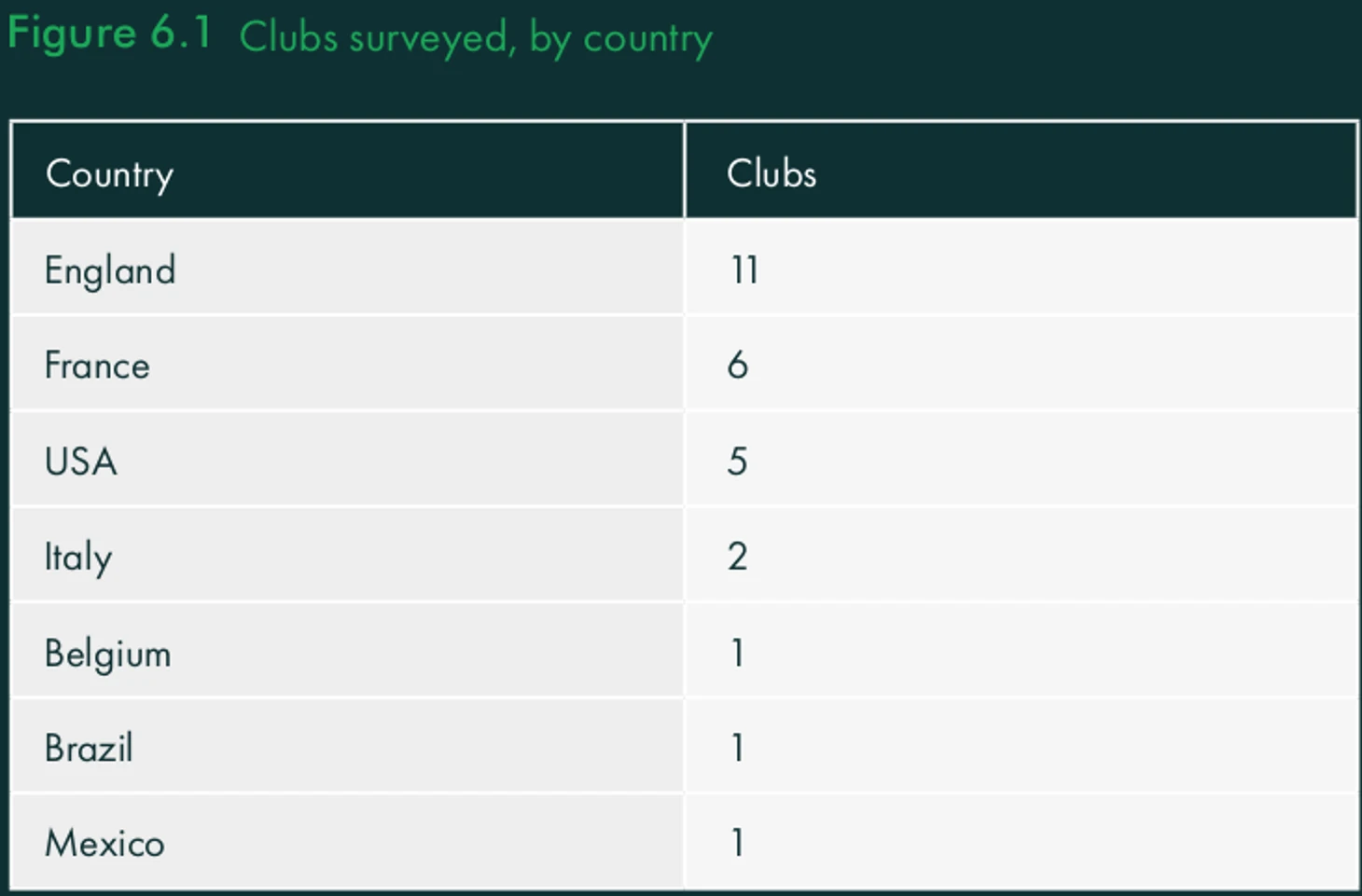
В предисловии скажу о структуре отчёта и его ограничениях. Во-первых, отчёт построен на ответах представителей всего 27 клубов мира. Представительство стран указано в таблице ниже. Что это за клубы в отчёте не сказано (разве что бельгийский клуб – это практически точно Брюгге), но скорее всего это довольно богатые и успешные команды и/или из стран с высокой культурой аналитики в спорте (США). Так что цифры в отчёте нужно воспринимать через призму того, что в опросе участвовал «золотой процент», поэтому проблемы и боли в аналитике этих команд могут слабо коррелировать с нуждами среднего по больнице клуба. Тут уж «У кого-то щи пустые, а у кого-то жемчуг мелкий». Но тренды, описанные в отчёте, хорошо ложатся на индустрию в целом, так что будут полезны всем.
Второе ограничение касается меня. Я аналитик данных, но в спортивной статистике просто любитель (да и то в баскетбольной), поэтому я могу не знать многих тонкостей и «внутренней» кухни аналитики в футболе. Где-то это неважно (часть про технологии), где-то важнее (данные, процессы). Это, вкупе с довольно поганым английским, могло привести к тому, что я где-то в отчёте что-то неправильно понял. Так что если Вы прочитаете оригинал работы и найдёте у меня ошибку, напишите об этом в комментариях.
Представительство клубов по странам
Отчёт делится на 4 раздела:
Данные. С какими данными из каких источников работают клубы, как происходит их интеграция.
Технологии. Какие системы, приложения, языки программирования используются в работе
Люди. Наличие аналитического отдела в клубе и его компетенция. Также здесь рассматривается проникновение аналитики в другие подразделения клуба: рекрутинг, sport science и т.п.
Процессы. Насколько развиты процессы построения аналитики в клубе. Например, обработка данных это автоматизированный конвейер с их очисткой и трансформацией или «мы собрали 100 экселек, потом соединили их в одну».
В этом обзоре на обзор я буду придерживаться структуры самого отчёта от Left Field. Оригинал можете скачать по ссылке.
Данные
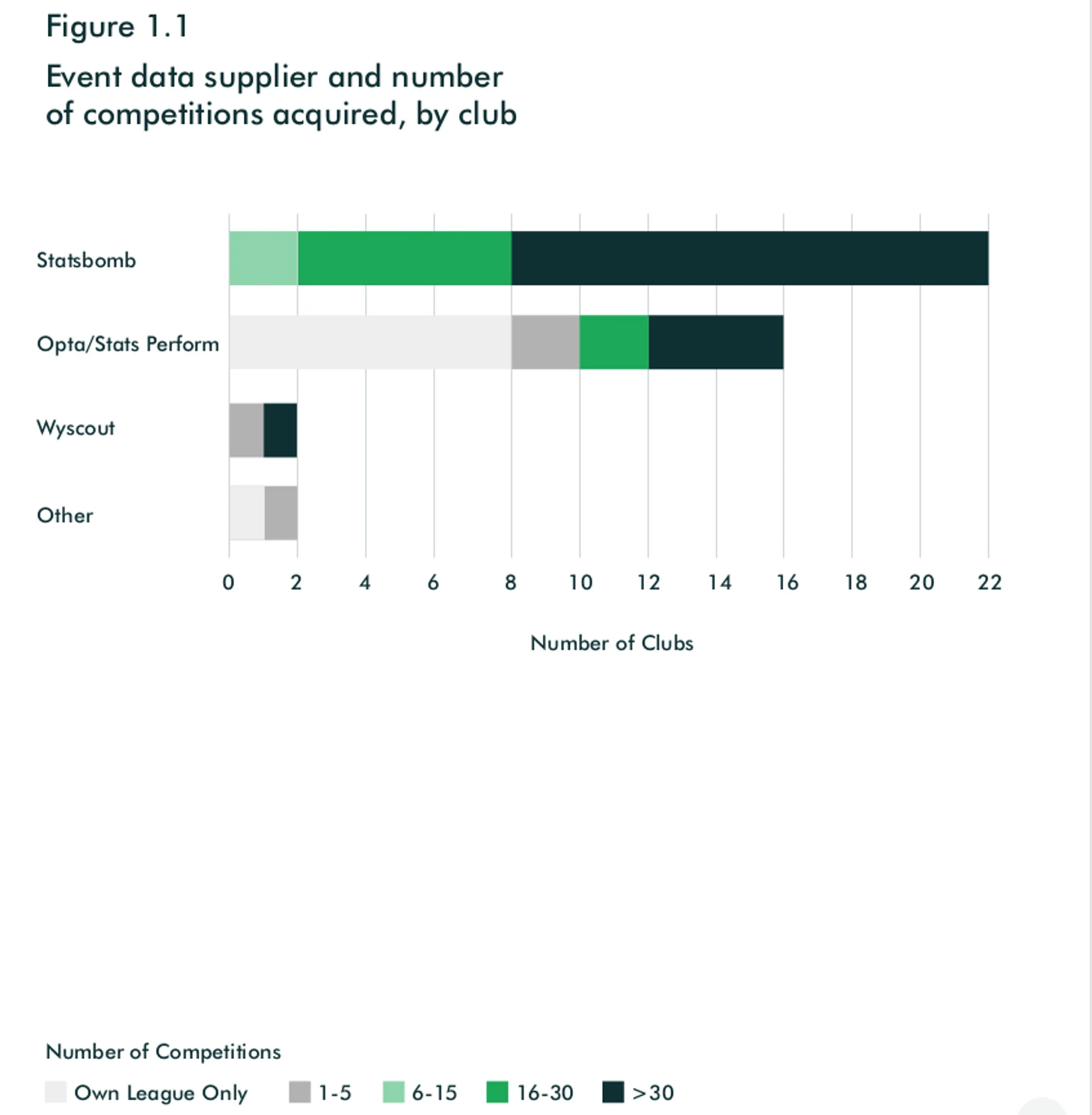
Данные в футболе делятся на несколько видов. Самые главные и очевидные – это event и трекинг данные. Event данные – это информация о всех событиях в игре. Пас, удар, фол, верховое единоборство и т.д. На картинке ниже можно увидеть какими операторами event данных пользуются клубы и о каком количестве лиг получают информацию. Только один клуб не приобретает event данные. Лидерами среди поставщиков являются Statsbomb и Opta. Причём если у первых нет клиентов с пакетом менее 6 лиг, то у Опты ровно половина покупает только свою Лигу. Возможно причина этого кроется в пакетном предложении и ценовой политике поставщиков. Также, если сложить все столбики получится число заметно больше 27. Это значит, что некоторые клубы покупают данные у нескольких поставщиков. Например у Опты свою лигу (возможно их данные более качественные/глубокие), а у Statsbomb остальные (например, потому что данные от них дешевле). Клубы предпочитают забирать у поставщиков «сырые» данные и строить свои BI-системы, нежели покупать готовые решения.
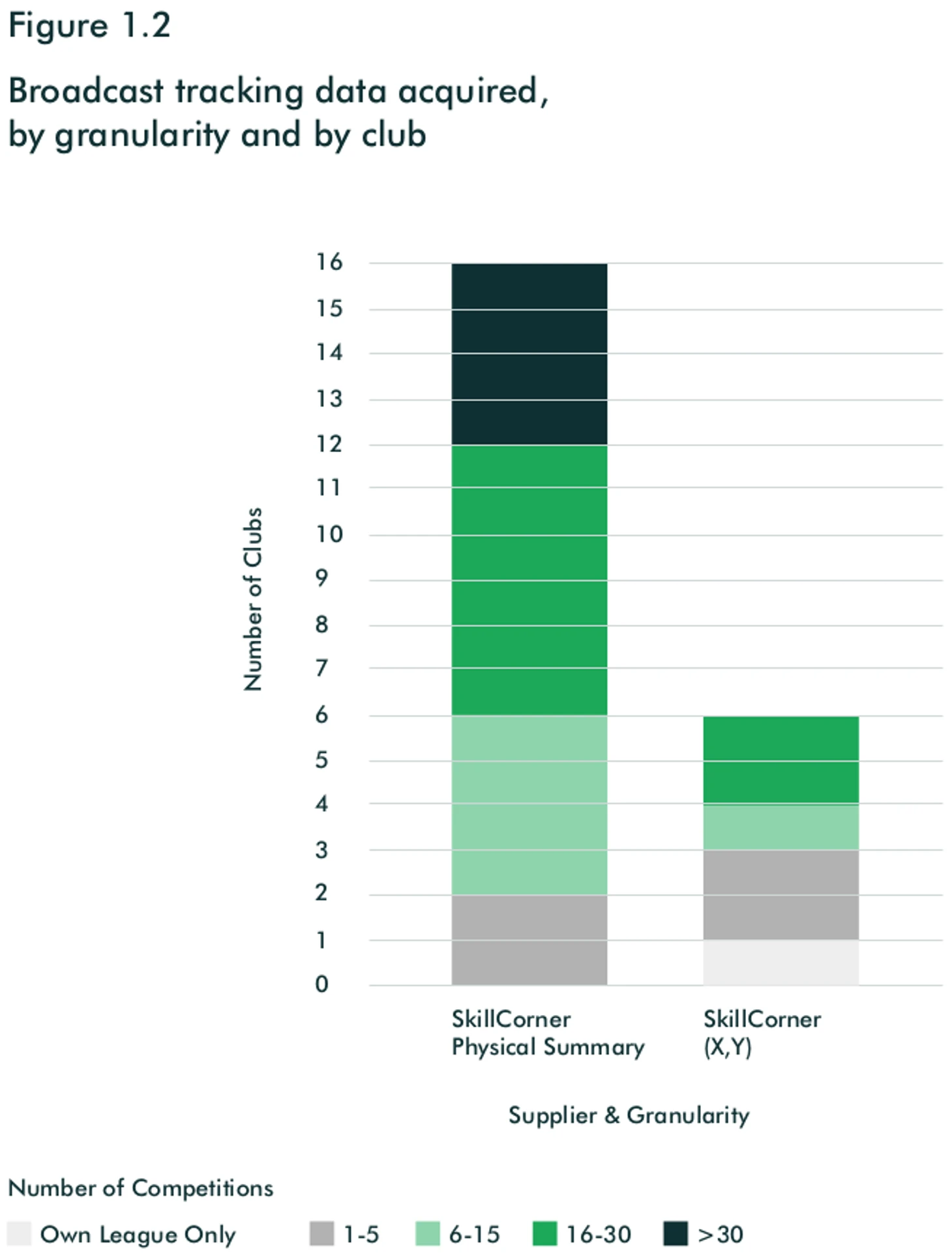
Трекинг данные – это информация о передвижениях игроков по полю. Каждый клуб из топ европейских дивизионов, а также MLS, имеет доступ к трекинг данным внутри Лиги благодаря общелиговой сделке с одним из 3 поставщиков: Stats Perfom, Second Spectrum, Tracab. Здесь ситуация обратная, многие клубы не используют в своей аналитике «сырые» данные, ограничиваясь «physical summary» от поставщиков.
Помимо этого, 16 из 27 клубов получают broadcast данные (трекинг по видеотрансляции посредством технологий компьютерного зрения). Все они покупают данные у SkillCorner, 6 клубов приобретают подробные данные. Тут было бы интересно узнать, что такого может предложить SkillCorner с трансляций, что клубы приобретают его услуги помимо общего поставщика данных у которого должно быть больше возможностей для качественного трекинга.
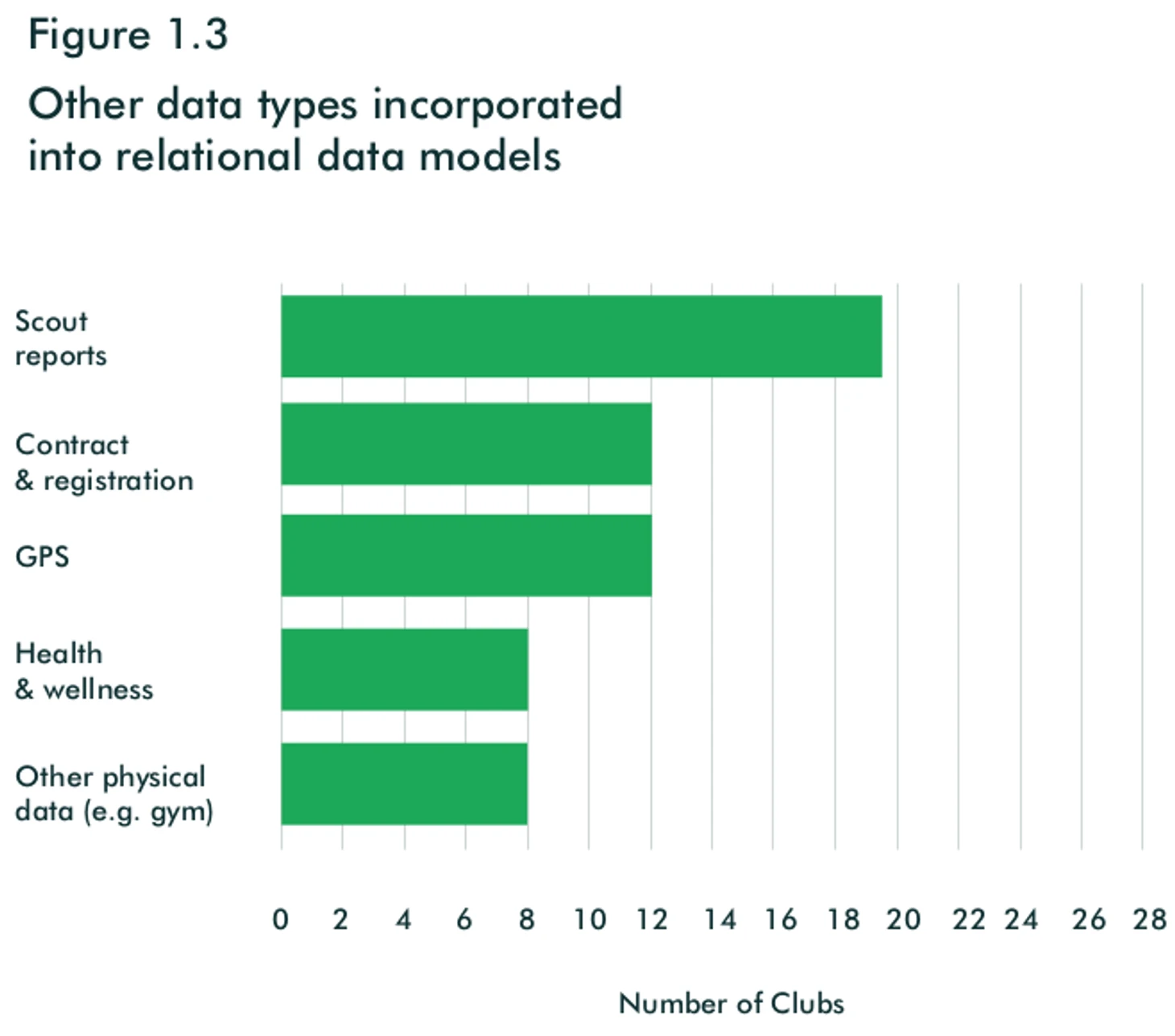
В раздел «Другие данные» попали данные, которые используют другие отделы клубов. Обычно эти данные живут сами по себе, не встраиваются в общий конвейер и не обогащают собой event и трекинг данные, что на самом деле выглядит как упущение и точкой роста.
Технологии
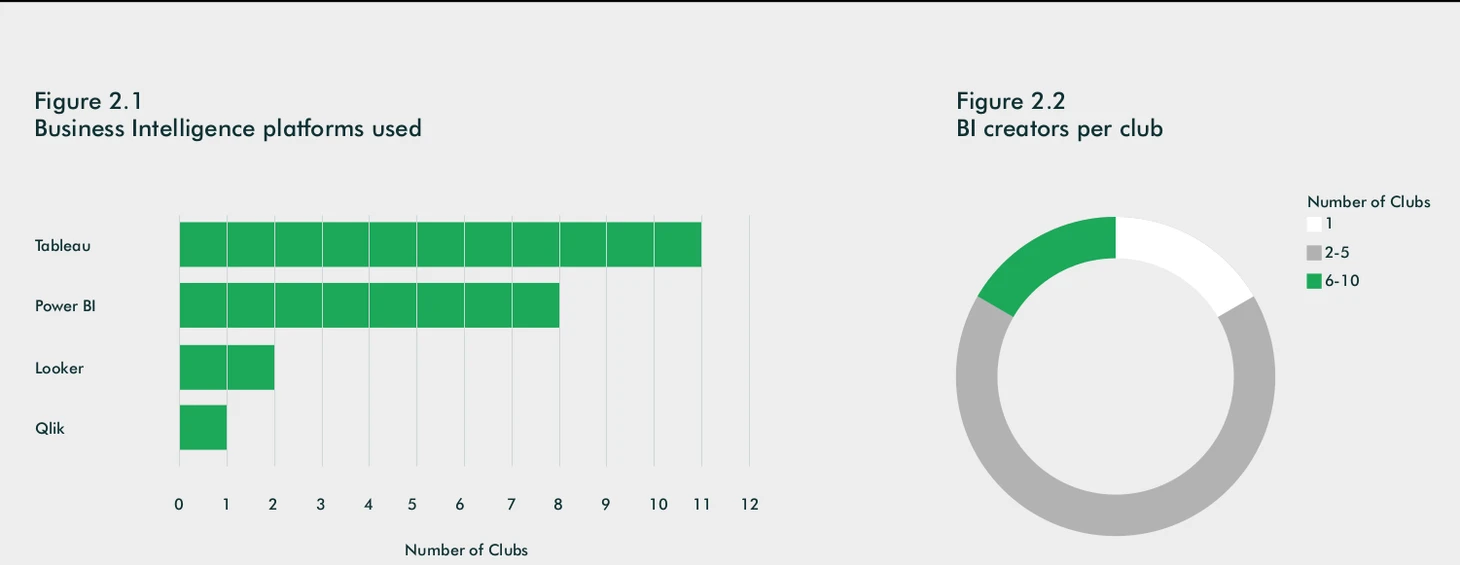
В этом разделе авторы сделали несколько подразделов и начнём с BI. Визуализация данных, их грамотная компоновка и представление является важной частью «продажи» работы аналитика заказчику. Наглядный график с примитивной статистикой может быть полезнее ML модели, корректно объяснить работу которой в полной мере не способен даже сам её автор. Неудивительно, что именно BI развит в клубах очень хорошо (просто сравните с цифрами из следующего блока). 16 клубов используют BI-инструменты (лидеры Tableau и Power BI), 13 клубов также строят свои дашборды, в основном используя библиотеку RShiny. Тут ничего удивительного: Tableau и Power BI две махины в мире BI с огромным отрывом от остальных, а RShiny даёт хороший баланс простоты написания кода и сложности приложения (могу сказать как человек создавший на нём больше десятка разного рода приложений). Клубы серьёзно подходят к визуализации данных, поэтому обычно созданием дашбордов занимаются несколько человек.
Другая ситуация в Data Science и Machine Learning. В отчёте в этом подразделе вместо графика большая цифра «78». Сколько процентов (это 21 клуб) не используют ML в своей работе. В остальных обычно этим занимаются один-два человека, что не очень хорошо в плане поддержания активностей, например когда человек увольняется. ML решения часто покупаются у вендоров, но если разрабатываются свои модели, делается это на открытых библиотеках, а не облачных инструментах а-ля AWS.
С одной стороны ситуация грустная, с другой понятная. Разработка модели это долгий серьёзный процесс без гарантий успеха (по разным причинам модель может не работать). Это, а также скептицизм со стороны заказчика, например тренерского штаба, в качестве работы модели («я сорок лет в футболе, я лучше знаю») и её «целях» («хотят заменить всех роботами») тормозит внедрение ML в футбольную аналитику. Но, как мы видим на примере ChatGPT, это неизбежный процесс. И те, кто поймёт это раньше, а главное как эти решения интегрировать в работу аналитического отдела и клуба в целом, получат большое преимущество.
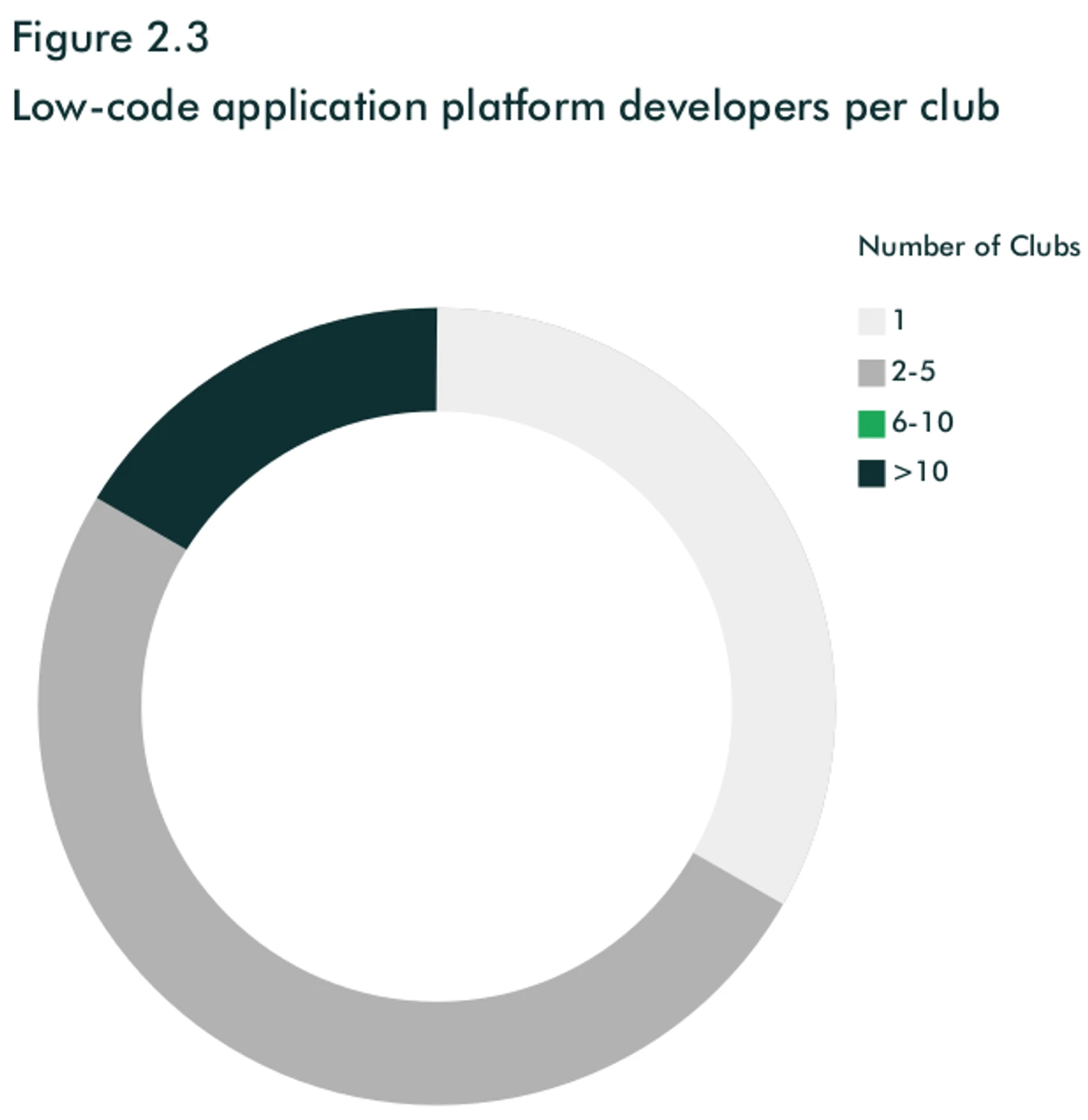
Low-code приложения, чтобы это не значило, используют также только шесть клубов, в основном для сбора информации с поля: тренировочные сессии, набор в академию и т.п.
Использование облачной инфраструктуры имеет свои преимущества (как сказано в буклетах и на сайте AWS): лёгкая масштабируемость, экономия на дата-инженерах (что неправда), за вас уже всё создали и настроили. 21 клуб используют облачные платформы, лидер с большим отрывом AWS. Интересно, что здесь сумма также больше 21, т.е. у кого-то есть 2+ платформы. Возможно на это есть логичная причина, но со стороны выглядит как создание проблемы на ровном месте.

Ну и последний график в этом разделе это языки программирования, которые используются в работе. Авторы отчёта намешали в одну кучу и ЯП и просто фреймворки (RShiny, PySpark). Тут анализировать особо нечего: золотая тройка аналитика: SQL, Python, R здесь в топе. JS используют в командах, где пилят свой собственный фронтенд, остальные языки довольно частные случаи.

Люди
23 из 27 клубов имеют централизованный отдел аналитики, обычно размером 1-2 человека. Средний опыт вне футбола 3 года. Авторы отчёта считают, что должно быть движение в сторону того, что централизованные отделы будут заниматься развитием процессов в работе с данными (получение, очистка, трансформация и объединение), а также развитием сложной статистики и ML (разработка метрик и моделей), а вот простые отчёты должны анализировать люди «на местах», поэтому нужно повышать их уровень в аналитике данных.

Помимо центрального отдела неплохо владеют аналитикой в отделах рекрутинга, sport science , анализе продуктивности. А вот тренерский штаб обычно использует подготовленные отчёты в центральном отделе и сами не занимаются работой с данными. В этом есть и плюсы, и минусы. Минус в том, что отдел аналитики становится бутылочным горлышком через которое должны протекать все данные, метрики, дашборды. Учитывая обычно небольшой размер этих отделов это негативно сказывается на развитии аналитики в клубе: вместо действительно сложной работы, которую за него никто не сделает, аналитик описывает три столбчатых диаграммы, на которых итак всё понятно. С другой стороны такая централизованность снижает риск неверного анализа и, как следствие, принятие неправильных решений из-за низкой квалификации человека, который выполняет функции аналитика (например тренер). О пути решения этой проблемы сказано в предыдущем абзаце.
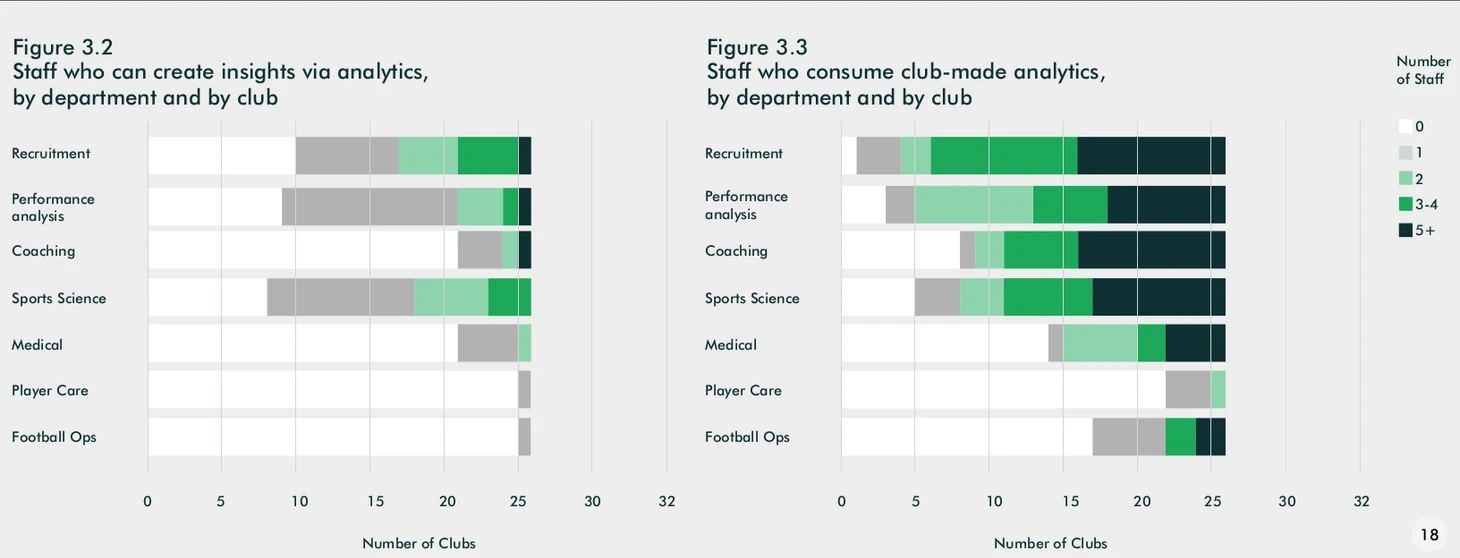
Сейчас очень много внимания в клубах уделяется на «внешнюю» составляющую аналитики: визуализацию и разработку метрик. Это связано с тем, что многие клубы только вначале пути и для её «продажи» внутри клубов нужны красивые графики и дашборды. Большее проникновение аналитики в футбол, как надеются авторы отчёта, приведёт к тому, что потребители (игроки, тренеры и т.п.) привыкнут к аналитике как части своей работы и будут готовы работать с менее очевидными вещами (ML).
Процессы
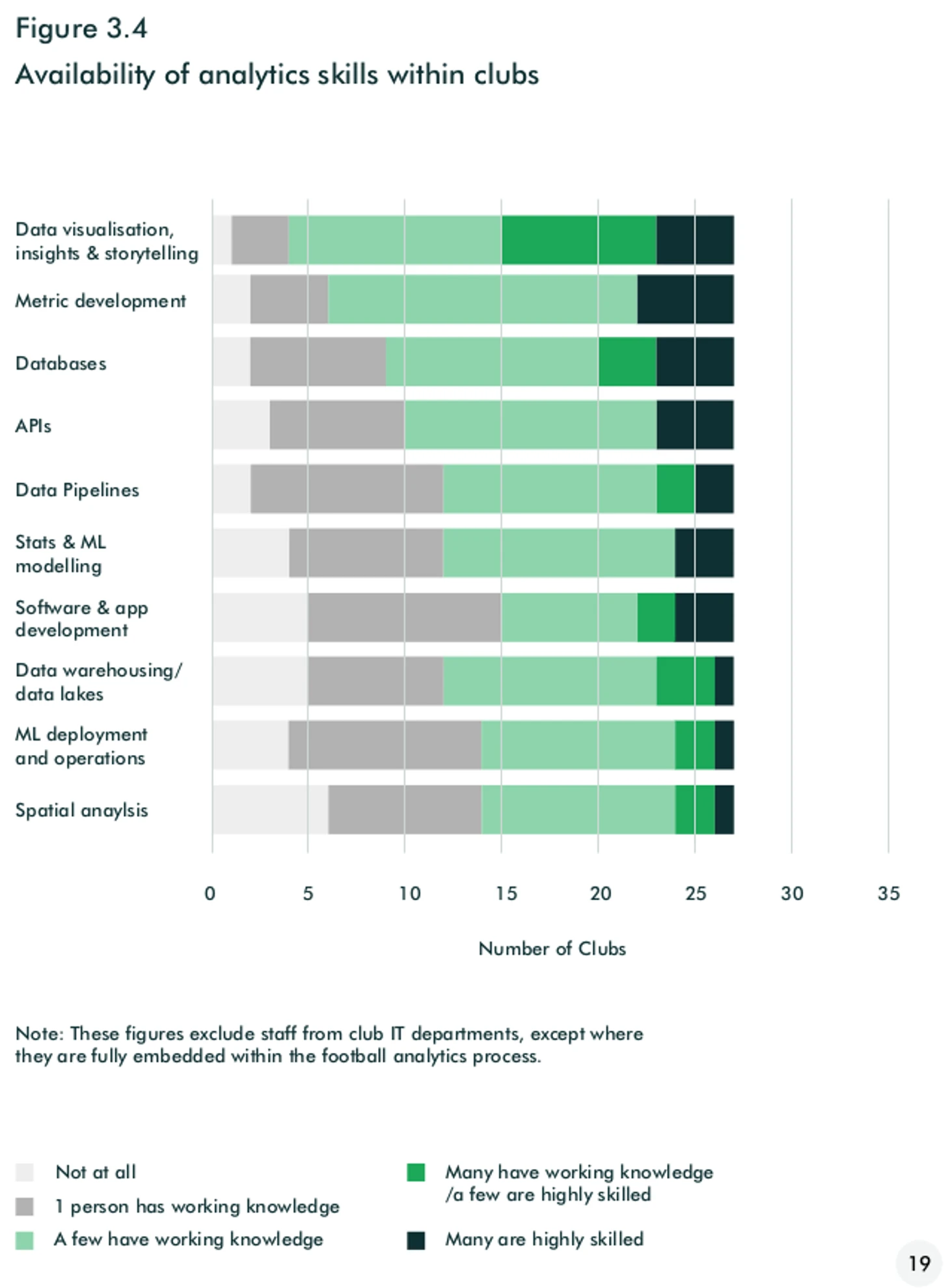
В клубах хорошо развит data storytelling (представление данных в понятной форме для принятия решений). Автоматизирован сбор данных, их очистка и конвейеры их обработки. По мнению CEO Twenty3, главные проблемы в работе с данными находятся на входе (правильная обработка данных из разных источников) и на выходе (предоставление нужной информации в понятной форме для пользователей с разным уровнем аналитических навыков).
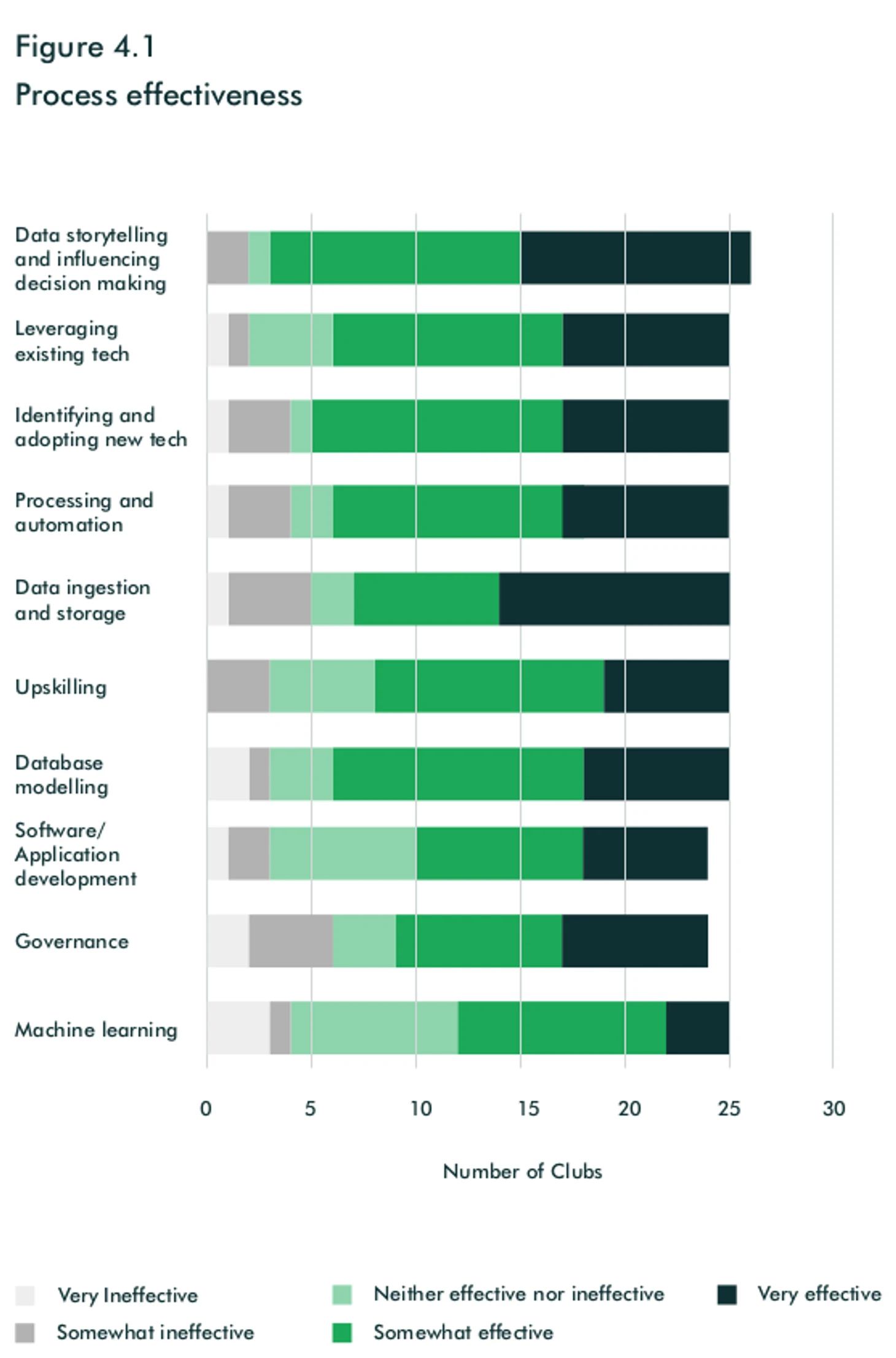
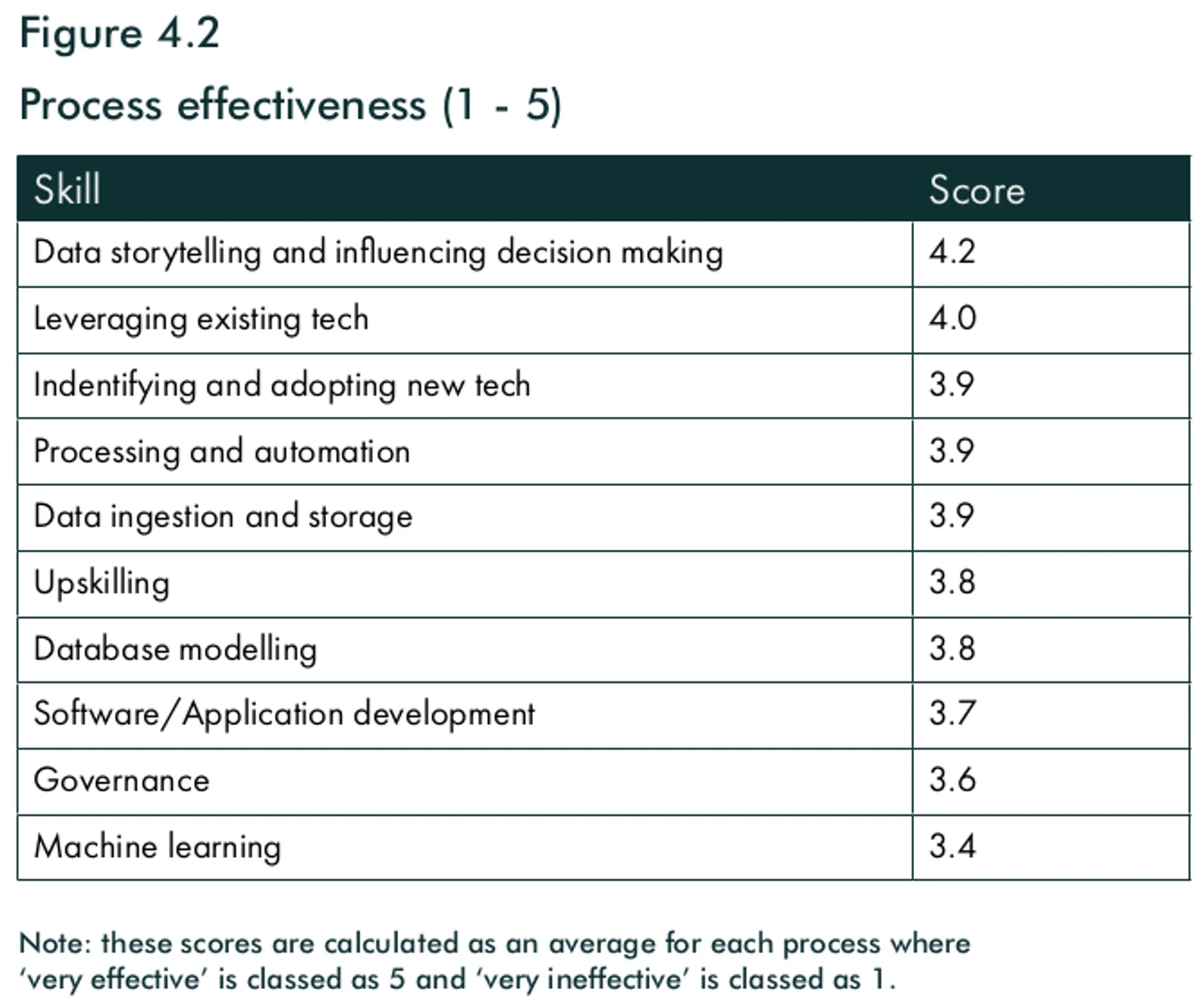
Взгляд в будущее
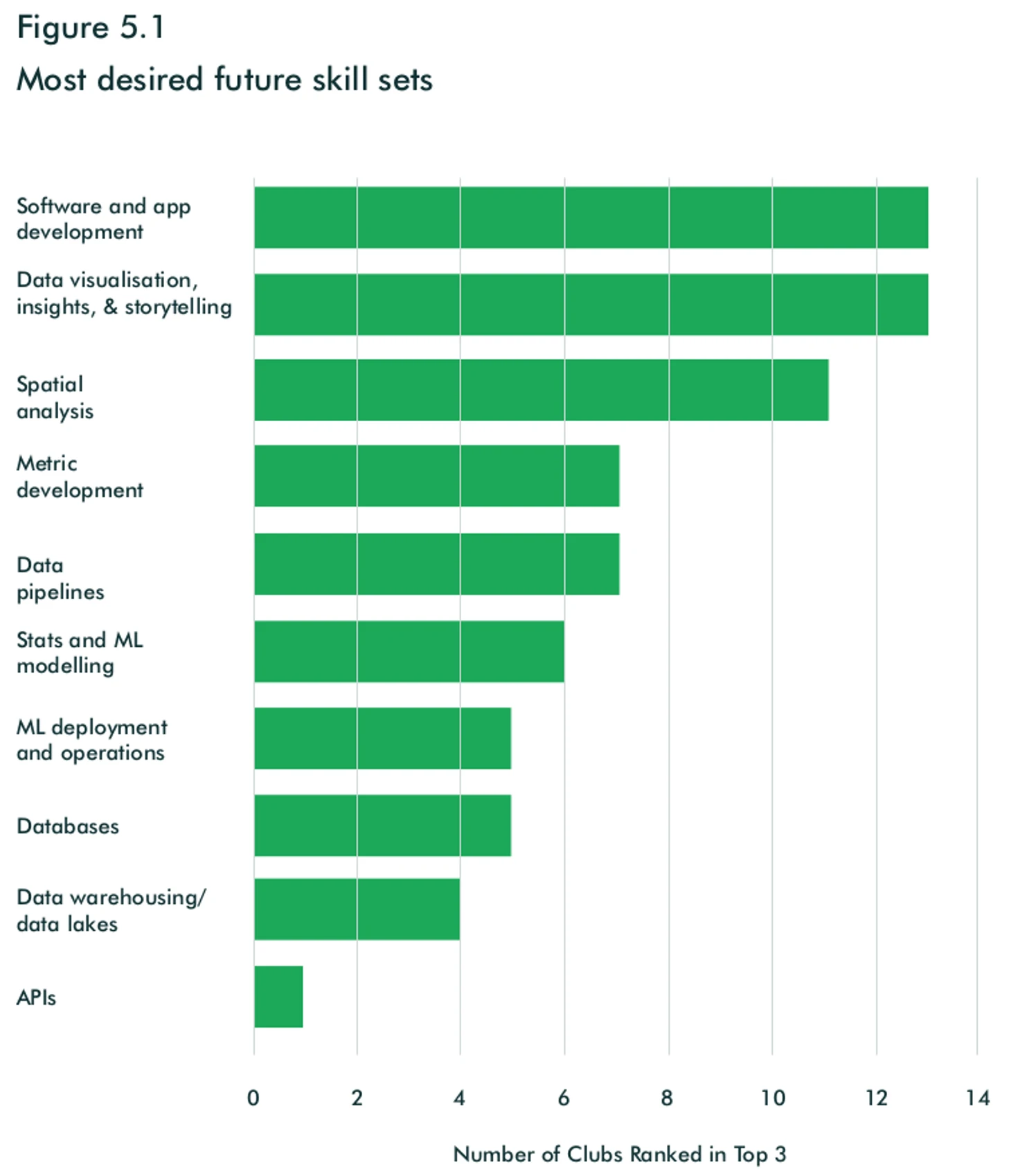
Несмотря на текущий уровень развития визуализации данных, этот навык большинство клубов хотят развивать и в будущем. Также клубы интересует возможность работать с пространственными данными(GPS) и разработка собственных платформ и приложений. ML не входит в топ навыков, которые клубы хотят развивать в перспективе, что вкупе с низким развитием сейчас говорит об отставании в этом компоненте футбола от остальных индустрий.
Аналитики считают заинтересованность в данных высшего руководства клубов, как пользой, так и угрозой. Также угрозой считаются некачественные данные и ошибки в использовании.
Это мой первый пост в новом блоге. Надеюсь он был Вам интересен. Цель этого блога рассказывать о крутых вещах в спортивной аналитике во всём спорте. Кому-то я могу быть известен как автор блога «По ту сторону Атлантики», где я рассказываю (редко в последнее время) про статистику в НБА и делюсь своими наработками.
Если Вам понравился пост, подпишитесь на блог и на мой телеграм-канал Цифры в спорте, где я пишу о применении Data Science в спорте.








Не очень понятна популярность "облаков". Больших данных нет, облака дорогие, а бюджеты низкие.
Думаю тут дело в том, что для своего железа нужно иметь девопса, который будет всё это настраивать. А если он уволится? А так накликал, что нужно и спишь спокойно (в теории).