Составляем рейтинг европейских лиг с помощью Glicko-2 и объясняем почему он лучше рейтинга УЕФА

В предыдущей статье с помощью рейтинг-системы Glicko-2 мы оценивали силы команд Лиги 1. Полученные рейтинги позволяли нам прогнозировать результаты будущих матчей. Тоже самое можно проделать и для других национальных чемпионатов.
Недостаток такого подхода в том, что оценки сил команд будут адекватными только в пределах одной лиги. Мы не можем просто взять и сопоставить рейтинг «ПСЖ» с рейтингом «Баварии», не говоря уже о паре «Байер» – «Рейнджерс», так как команды добывали свои рейтинги в разных по уровню чемпионатах.
Идея
Glicko-2 обладает интересным свойством. Рейтинг команды внутри формул не существует сам по себе, а только в связке с рейтингом соперника. Когда нам нужно посчитать вероятность победы, нам нужно знать разницу рейтингов команд. Такая же история с обновлением рейтинга. Это свойство дает нам право ко всем рейтингам команд одного чемпионата добавить некоторое число. Это ничего не сломает, так как (x+c) – (y + c) = (x – y).
Таким образом, добавляем в модель новый параметр рейтинг лиги. Это никак не повлияет на прогнозирование матчей внутри чемпионата, но отразится на матчах еврокубков (если соперники из разных чемпионатов), потому что рейтинги лиг будут разными. Технически мы просто перед началом сезона каждой команде присвоим не стандартный рейтинг 1500, а 1500 + c, где c зависит от чемпионата и может быть отрицательным.
Данные
Обучать модель будем на результатах матчей последних трех сезонов 30 национальных чемпионатов, а также матчах ЛЧ и ЛЕ.
Как посчитать рейтинги лиг?
В прошлой статье рассказывалось, как подобрать параметры преимущества домашнего поля и склонности к ничье. Их мы подберем для каждого чемпионата отдельно. Похожим образом будем подбирать рейтинги лиг, только на матчах международных кубков. Оптимальными параметрами будут такие числа, при которых точность прогноза матчей международных турниров будет максимальной. Преимущество домашнего поля будем считать равным среднему по лигам команд-соперников. Также поступим с параметром склонности к ничье.
Боремся с инфляцией
Команды, принимавшие участие в еврокубках, но без информации о выступлении в национальных чемпионатах получат некоторый рейтинг и параметры по умолчанию. При этом проигнорируем матчи в еврокубках между командами, о которых мы ничего не знаем. Иначе это может вызвать эффект инфляции: слабые команды, обыгрывая примерно такие же слабые команды на первых стадиях ЛЧ или ЛЕ, зарабатывают свой рейтинг и в более поздних стадиях выглядят фаворитами в матче против сильного соперника.
Поясним на примере. В текущем розыгрыше Лиги Европы в предварительном раунде косовский «Фероникели» обыграл гибралтарский «Линкольн» и андоррскую «Санта-Колому». В следующем раунде его ждал «Нью-Сейнтс» из Уэльса, которому «Фероникели» уступил. С точки зрения модели «Фероникели» выглядел фаворитом, так как имел две победы в двух матчах, а валлийский клуб не провел ни одной игры. Так как «Нью-Сейнтс» одержал победу над фаворитом, он получит существенную добавку к рейтингу. В следующем раунде валлийский клуб встретился с «Копенгагеном», история матчей которого известна. Однако так как Дания не является топовым чемпионатом, в данном матче «Нью-Сейнтс» будет фаворитом, что абсурдно.
Преимущества вышеописанного подхода
Модель учитывает уровень соперников. Победа над «Ливерпулем» должна цениться выше, чем над... не «Ливерпулем».
Модель учитывает текущую силу команды во время участия в еврокубках. Это помогает более трезво оценивать силу лиги в том плане, что если команда в прошлом сезоне играла хорошо (потому и попала в еврокубки), а в этом сезоне играет хуже, то модель через рейтинг команды учтет это. Разберем на немного искусственном примере: «Ростов» в текущем сезоне играет явно лучше, чем тульский «Арсенал». Однако «Арсенал» участвовал в ЛЕ, из которой быстро вылетел. Если бы на месте «Арсенала» оказался «Ростов» (то есть тоже бы вылетел от «Нефтчи»), то рейтинг России пострадал бы больше, так как рейтинг ростовчан выше рейтинга туляков в этом сезоне. Таким образом модель неявно учитывает, что представители страны в еврокубках могут не являться лучшими командами в лиге на данный момент.
Рейтинги лиг неплохо интерпретируются. Например, разница в 200 баллов между рейтингами означает, что прогноз на матч между средними командами на нейтральном поле будет примерно таким: 62% на победу фаворита, 22% на ничью, 16% на поражение. 100 баллов дадут распределение: 49%/27%/24%. 50 баллов: 42%/29/29. 10 баллов: 37%/29%/34%. Да, “средняя команда” – это весьма абстрактное понятие, но это явно лучше рейтингов УЕФА, с которыми вообще непонятно, что делать.
Результаты
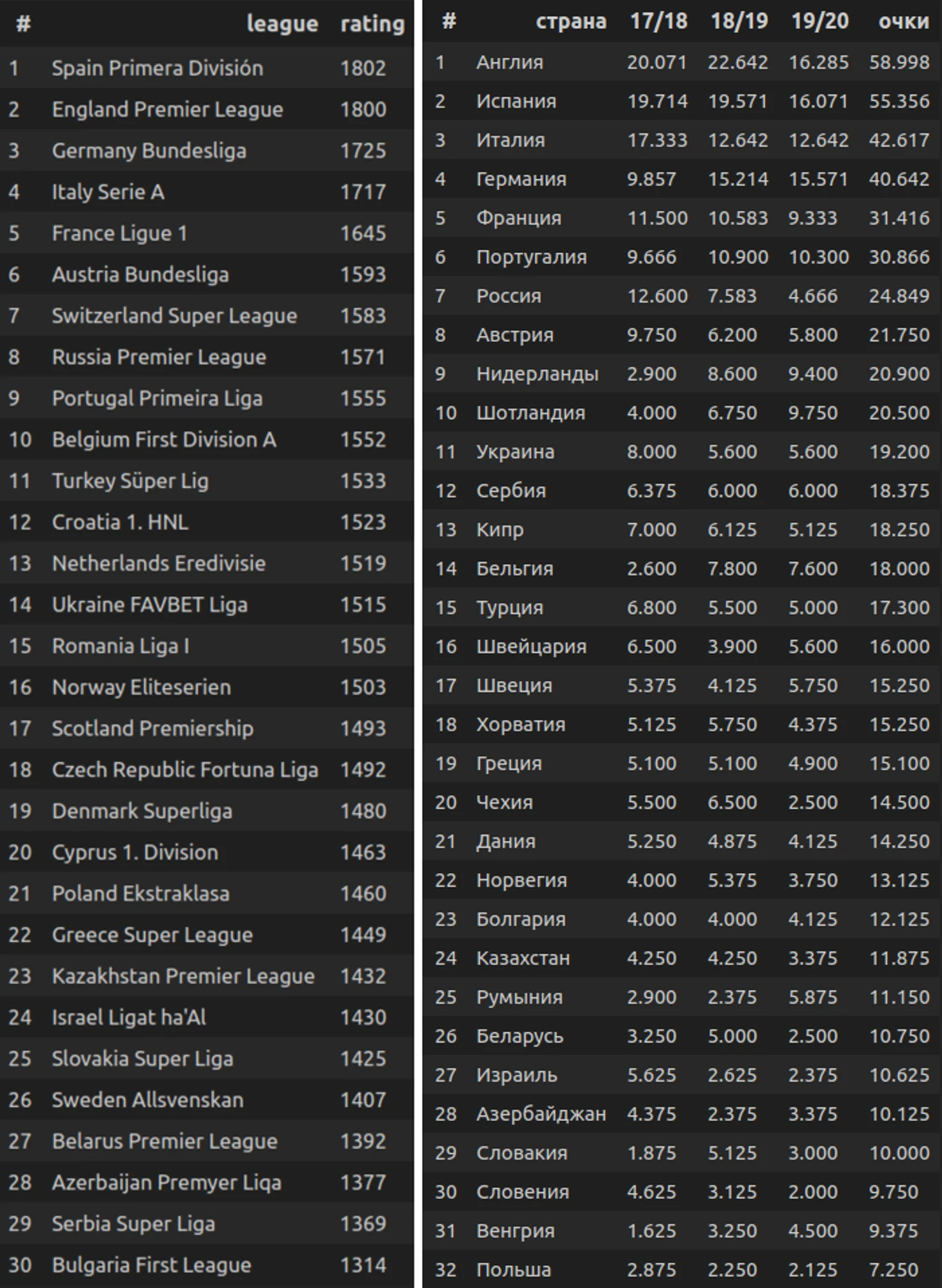
На фото представлены рейтинги лиг по итогам последних трех сезонов, включая текущий, а также рейтинг УЕФА за этот период.
















Что такое 1500+c - по факту это средний рейтинг команды конкретной лиги. Очевидно, что средний рейтинг команды Испании должен быть выше рейтинга команды Андорры. Но поскольку это математика, то перед началом расчета рейтинга все лиги равны. В вашем случае вы вводите некую переменную c, хотя логичнее оставаться в рамках классической модели и просто расчитать рейтинг с учетом полной базы футбольных матчей. Это естественным образом (за счет матчей в еврокубках) опустит средний рейтинг команды лиги на его значение.
Это поможет и в проблеме из раздела "Боремся с инфляцией" - почему вы допускаете, что у какой-то команды нет истории матчей в чемпионатах? Такое допущение хоть и не превращает всю идею подобного рейтинга в тыкву, но добавляет большую долю условности.
Также надо отметить, что в glicko-2 уже есть переменная волатильности. Если команда в рейтинге новая и имеет несоответствующие своему рейтингу результаты матчей, то у нее высокое значение волатильности, что будет очень сильно влиять на ее рейтинг. Благодаря этому рейтинг быстро примет свое реальное значение. Из этого следует, что прогнозировать результат матча следует не из рейтингов двух команд, а из пары рейтинг/волатильность.
Сам термин инфляции в контексте Глико вы описали неправильно. Это не про отсутствие данных о матчах, а о том что мы не можем доверять рейтингу, заработанному в прошлом - со временем он обесценивается, т.е. происходит его инфляция.
Параметр с в модели обучается на результатах матчей, поэтому не является субъективным. Давать всем командам одинаковый рейтинг на старте - не самая лучшая идея. Зачем нам ждать пока модель сообразит, что условный "Атлетико" является топовым клубом в Европе, а не только в Испании, а, скажем, "Локомотив" силен в РПЛ, но в Европе показывает средний результат, если мы можем дать командам еще до начала сезона некоторые априорные оценки. К тому же матчей в еврокубках не так много, поэтому мы можем просто не дождаться момента, когда рейтинги сойдутся к истинным значениям.
В последних двух абзацах вы описываете параметр rating deviation, который в модели есть, но не имеет никакого отношения к проблеме инфляции из статьи. Я описал проблему, когда есть команды из слабых чемпионатов, которые играют в еврокубках пару матчей, вылетают и тем самым раздают свои рейтинги. Почему по этим командам нет истории матчей в чемпионатах? Было лень собирать)
Ваше предложение "запустить" классическую модель имеет право на жизнь, но матчей в сезоне не так много, поэтому приходится вводить дополнительные параметры.
Еще раз спасибо за комментарий.