Statsbomb Innovation in Football Conference 2019

Если Вы следите за сферой футбольной аналитики, то, конечно же, знаете о компании Statsbomb. Если нет, то Statsbomb – компания, основанная Тэдом Кнатсоном, который сперва работал в британской букмереской конторе Pinnacle, а затем был главой аналитических отделов в «Мидтъюлланде» и «Брентфорде».
С помощью Кнатсона и его команды из нескольких человек, эти клубы в середине десятых сделали большой акцент на использовании футбольных данных (почитать про «Брентфорд» можно здесь, а про кейс «Мидтъюлланда» – здесь). Примерно в то же время и была основана Statsbomb, специалзирующаяся сначала на консультировании по аналитике и тактике, а теперь уже ставшая и провайдером данных. Помимо этого, компания выпускала (и выпускает до сих пор) большое количество аналитических статей, которые во многом задают тренды в футбольной аналитике.
Летом Тэд анонсировал проведение первой конференции на «Стэмфорд Бридж» в октябре, и это был отличный шанс узнать о самых актуальных исследованиях, а также пообщаться напрямую с аналитиками ведущих европейских клубов и с энтузиастами из твиттер-коммьюнити.
Расписание конференции было многообещающим и позволяло послушать доклады разных людей из мира футбола. Работало 2 секции – для функционеров / тренеров / медиа и секция для аналитических гиков.
Попасть во вторую секцию мог любой желающий – нужно лишь было до 21 августа отправить аналитическую идею с объяснением и реализовать ее, используя данные одного или двух сезонов топ-5 лиг – 17/18 или 18/19. Отличный пример идеи – недавняя статья Даниэля Жолковского, выложенная в блоге Дивергенция футбольного поля.

Выбор докладов был настолько большим, что даже до начала конференции я разрывался между некоторыми докладами. Немного повезло: на первом я случайно сел рядом с Ианом Грэхамом (главный аналитик «Ливерпуля», на русском можно прочитать о нем здесь, на английском – здесь) и решил, что мой выбор будет совпадать с выбором соседа.
Перед первым докладом приветственное слово взял сам Тэд: вкратце рассказал о компании, показал текущие разработки / успехи и обозначил цели на ближайший год. Из интересного: он показал платформу Statsbomb IQ – большой BI-tool с всевозможными визуализациями и сопутствующими типами анализа. Понять, что именно включает в себя этот тул, можно из статей аналитиков на сайте компании, но по сути – это грамотно собранные наработки аналитиков / дизайнеров визуализации в один удобный интерфейс. Во время конференции, кстати, можно было подойти к сотрудниками Statsbomb и попользоваться программмой. Конечно же, эта конференция задумывалась не только как некий академический сбор вовлеченных и интересующихся людей, а в том числе и как платформа для продажи продукта самой компании. Но это абсолютно нормально.
Теперь совсем вкратце практически о каждом из докладов. Я не буду слишком глубоко вдаваться в детали, перечислю только основные выводы и предположения, которые успел записать и понять в принципе. Все доклады были записаны на видео и будут выложены в скором времени на канал Statsbomb.
1. Tom Decroos – Is our model learning what we think it is learning?
Том с коллегами из университета Левена создал метрику VAEP (Valuing Actions by Estimating Probabilities), которая покрывает не только какое-то одно конкретное действие (как это делают xG, xA и тп), а несколько (как например, xGChain, xGAdded, xT, Attacking Contributions). Метрика является классификатором, будет ли забит/пропущен гол в течение следующих 10 действий и использует три типа переменных (простые – тип действия, результат...; сложные – расстояние до ворот, время между действиями...; контекстные – разница в счете) для оценки.
В этом исследовании для меня были важны технические выводы с рекомендациями для построения дальнейших моделей (если Вы не знакомы с анализом данных, то переходите к следующей статье) :
• Для оценки результата лучше использовать Normalized Brier Score вместо ROC-AUC кривой
• Generalized Additive Model подходит лучше для интерпретации результатов, а также показывает значение итоговой метрики, слабо отличающееся от алгоритмов бустинга
• Сокращение переменных до 10 слабо ухудшает качество классификатора и сильно сокращает скорость вычислений.
Помимо этого, Том рассказал о новом формате SPADL, который позволяет стандартизировать данные из источников (Wyscout, Opta, Statsbomb) и приводить их из вида словарей-json в вид табличек. Это довольно интересно, тем более, что Ливерпуль озадачивался в прошлом сезоне этой проблемой.
Для интересующихся: ссылка на код и библиотеку Python c реализацией формата
2. Robert Hickman – Considering defensive risk in Exptected Threat models
Ожидаемое расширение идеи Каруна Сингха: внедрение защитных характеристик в модель ожидаемых угроз. Честно говоря, я сам сейчас разрабатываю схожую модель, мои мысли по этому поводу совпадают с идеей Роберта.
Проблема текущей модели xT заключается в том, что она:
• Не «наказывает» игроков за потери мяча, и соответственно, поощряет более спекулятивные пасы. Пример: карты пасов Шелви и Крооса, где видно, что Кроос больше «разгоняет» владение по всему полю.

• Не учитывает пасы/владение глубоко в защите, которое может привести к потере мяча и пропущенному голу. Поэтому в уравнение добавляется отрицательная компонента, отражающая риск от перемещения мяча назад.
• Не учитывает возможность удара по воротам вместо паса (по идее, xG удара – первая компонента в цепи Маркова, но ударом может быть не обязательно только последнее действие в атаке).
Учитывая эти факторы, Роберт составил свою модель по топ-5 лигам и получил следующие результаты:
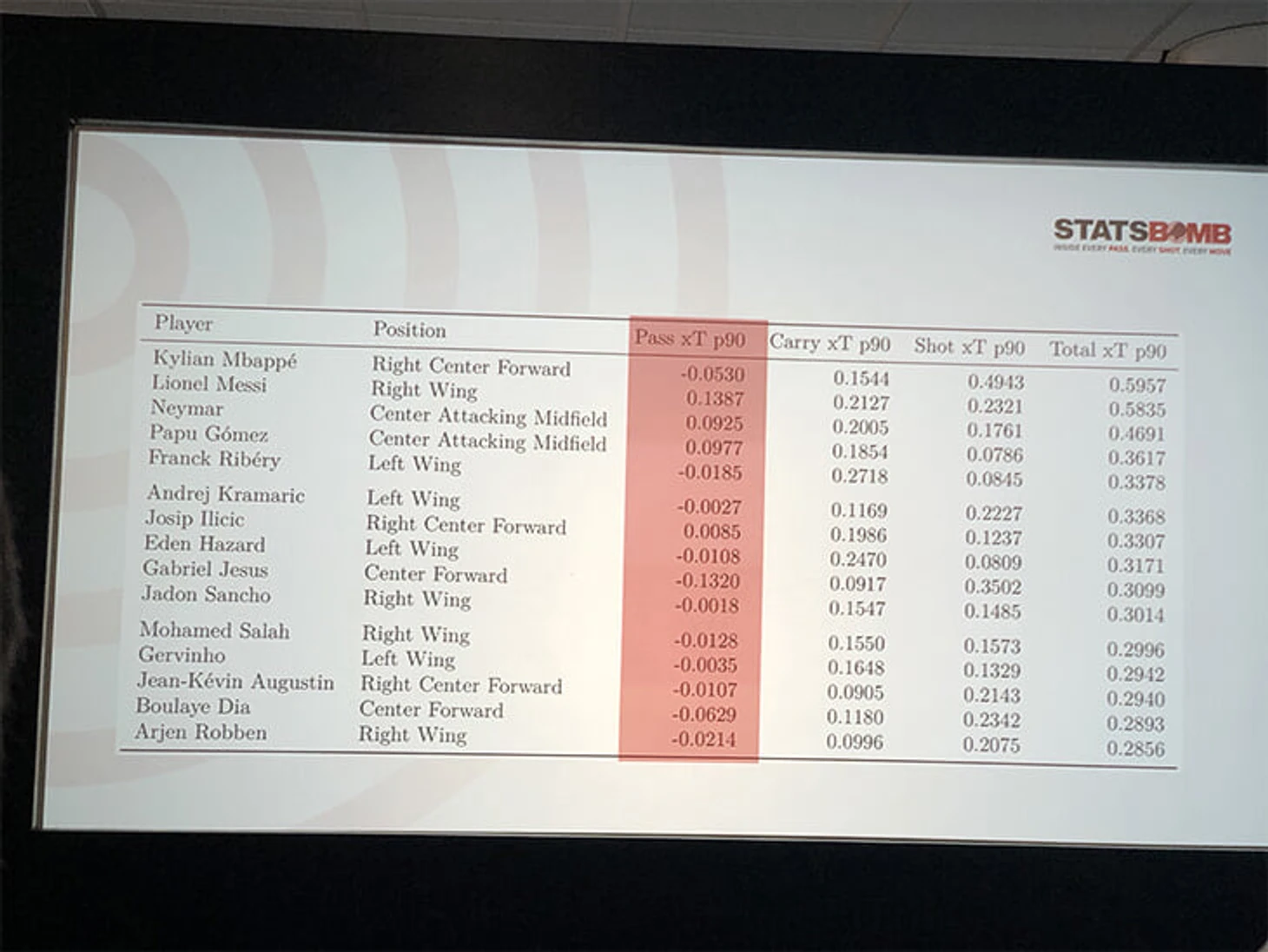
3. Javi Fernandez – Finding the free man: a contextual approach for identifying spaces that matter
Как мне показалось, глава отдела спортивной аналитики «Барселоны» не сказал ничего радикально нового в своем докладе и повторил презентацию, показанную на Sloan этого года.
В принципе, Expected Possession Value была довольно-таки революционной метрикой в этом году и было бы банально сложно сделать что-то качественно новое за полгода, учитывая уровень занятости Хавьера и его команды.
Интереснее было услышать его мнение по некоторым аспектам из ответов на вопросы:
• В футболе тяжело предсказывать ходы ввиду сильной динамичности игры. Контрпример динамичной игры – шахматы, ведь это первый спорт, в котором ходы можно было просчитать, по сути, гигантским оптимизированным перебором и обеспечить победу компьютера над человеком. Неясно, как моделировать индивидуальные особенности игроков, поэтому очень важна коммуникация аналитиков с тренерами касаемо краткосрочных решений во время игры.
• Ставшая классической проблема коммуникации аналитиков и тренеров: важно внедрить культуру принятия данных, ведь данные позволяют понять игру лучше. В то же время сложно донести конкретно и ясно информацию до тренеров.
• Например, в случае с EPV идеально было бы подтверждать метрику с видео (что, в принципе, уже сделано), но возникает другая проблема – качество трекинговых данных. Очень много времени и усилий уходит на их предобработку/чистку.
• Проблемы перевода терминологии с языка клуба на английский и наоборот дополнительно усложняют процесс коммуникации.
4. Ryan Beal, et al – Valuing player influence within teams
Райан попытался с помощью теории графов оценивать степень вовлечения/важности игрока в командную игру. Имея данные по АПЛ за прошлый сезон, он анализировал графы владения мячом, выделял различные события в матчах, оценивал их веса во вклад в итоговый результат игры и на основе этого приходил к самым “командным” игрокам. Затем он анализировал самые “подходящие” друг другу пары игроков.
• Неудивительно, что и в одиночных рейтингах, и в рейтингах пар высшие места занимали игроки «Манчестер Сити» (Фернандиньо, Сильва, Лапорт. Уокер), так как более длинные владения зачастую приводили к голу и, соответственно, улучшали результат.

• Проблема в вычислительной способности данной модели: теоретически она позволяет подобрать целые команды игроков, но неясно, как учитывать неравное количество времени, проведенное на поле, и травмы.
5. Thom Laurence – Some things aren’t shots: comparative approaches to valuing football actions
Презентацию от текущего CTO Statsbomb (и бывшего аналитика пражской «Славии») было интереснее всего слушать, так как, во-первых, в ней были описаны совершенно новые технические вещи, а во-вторых, будучи хорошим рассказчиком, Том часто разбавлял доклад разными забавностями и не давал скучать аудитории. После релиза метрики, разработанной в «Барселоне», Статсбомб начал думать, как ее можно улучшить, ведь EPV не идеален: он во многом акцентирован на владении, не включает себя вторые мячи (second balls), риск потери мяча в защите, перехваты, а также розыгрыш мяча с центра поля, когда мяч сразу выносится в аут в сторону финальной трети (подробный разбор такого розыгрыша можно прочитать вот здесь)
Абсолютно логичное и закономерное техническое решение – использовать Reinforcement Learning. Вкратце – это область машинного обучения, в которой ИИ обучается не только на доступных исторических данных (как в обычном обучении с учителем), а взаимодействуя с окружающей средой. Придумать такие алгоритмы сложно, так как что многие передовые алгоритмы запатентованы (например, алгоритм NB от Google).
Статсбомб написал нейросеть, которая использует 8 возможных типов действий на поле и в итоге определяет вероятности того или иного исхода матча со временем. Вот пример графика одной из игр.
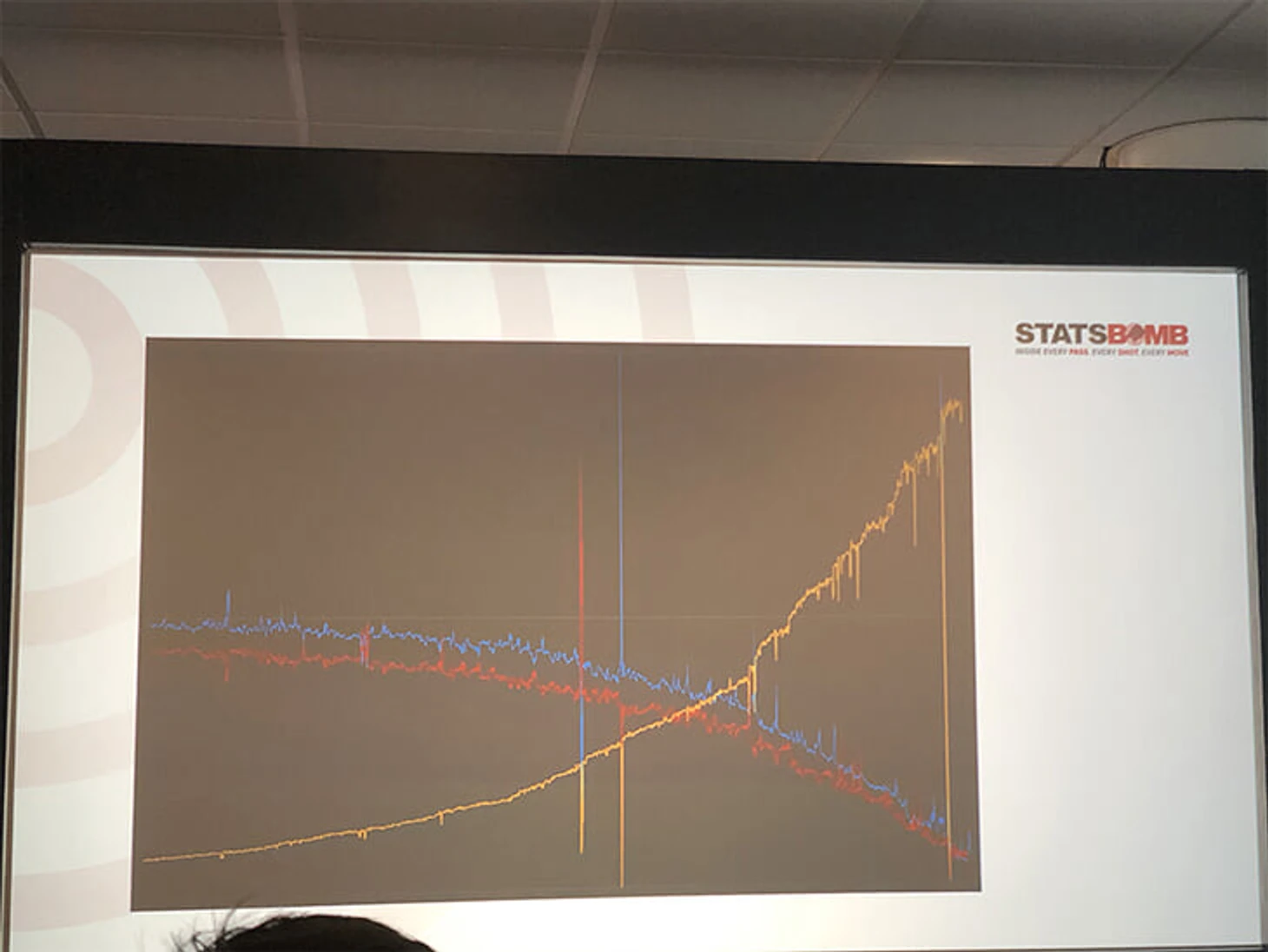
Синяя линия отображает вероятность победы, красная – поражения, желтая – ничьи. Видно, что на графике очень много пиков – это удары. Также видно домашнее преимущество (и это отдельный вопрос – как замоделировать и верно определить то, что его дает), увеличение вероятности ничьи к концу матча (что логично), а также странные колебания кривых к концу матча. При более точной настройки нейросети эти колебания должны исчезнуть, но пока что ближе к концу нейросети примерно без разницы на результат, и она задает его вероятности каким-то случайным шумом.
Также Том отдельно выделил базовые вещи, на которые стоит и нужно обратить внимание при моделировании любой модели в принципе:
• Нужно теститровать модель (и не только на экстремальных наблюдениях по типу Месси), а также проверять её на целесообразность в принципе.
• Многие модели сильнее оценивают атакующий вклад, нежели защитный; при моделировании стоит думать об устрашении этого смещения.
• Внедрение более детальных данных позволить делать модели точнее, но неясно, когда это будет.
Эту презентацию я особенно хочу пересмотреть, так как по моему мнению, это самое актуальное, что есть в открытом доступе сейчас в индустрии. Но следующие две я хочу посмотреть ещё и потому, что просто не успел записать и понять то, что было рассказано :)
6. David Perdomo, et al – How to break a set defence
Дэвид и его коллеги из компании Twenty3 выступали первыми и задались вопросом, какие атакующие события показывают атаку против «сложившейся» защиты и что на это влияет. Они выделили 4 фактора:
Длительность атаки (максимум 20 секунд)
Пинболл (моменты, когда владение мячом быстро переходит от одной команды к другой, то есть, своего рода пинболл, были исключены из рассматриваемого объема данных, критерий - объем владения обороняющейся команды должен быть не более 20 процентов от текущего владения)
Позиция центральных защитников (если они располагаются на высоте 43,75 метра)
Скорость атаки: (не менее 4.375 метра в секунду)

Когда владение мячом выполняет все 4 условия, владению присваивается позитивный лейбл (TRUE), иначе – негативный (FALSE). Затем для владений из класса TRUE считается вероятность окончания таких блоков действий голом (а также выяснется, что влияет на это), а для владения из класса FALSE каждая группа владений делится ещё на некоторое количество кластеров и анализируется подробнее. Исследование достаточно обширное с большим количеством технических деталей, поэтому полные выкладки можно почитать здесь.
7. Michael Caley: Passing, press-breaking and footedness: Exploring the Statsbomb’s new data
Имя Майкла должно быть знакомо любителям футбольной аналитики, он одним из первых создал свою модель xG и внёс большой вклад в её популяризацию. На самом деле Caley – его ненастоящая фамилия, настоящая фамилия Майкла – Haxby, но так как уже есть один известный Майкл Хаксби, он довольно долго искал себе новую фамилию :)
В своей презентации он делал акцент на метриках прессинга:
PPDA (Colin Trainor): количество успешных пасов до успешного защитного действия соперника
Moves Broken (Michael Caley): количество ситуаций, когда команда может прервать последовательность атакующих действий оппонента
CB Zone Passing (Paul Riley): количество пасов, оканчивающихся в "зонах действия" центральных защитников. Идея состоит в том, что команды с хорошим качеством прессинга не позволяют сопернику доводить мяч до этих "опасных" зон
High Turnovers Won (Anfield Index / Gaps Tandon): количество моментов, когда команда может перехватить мяч в атаке / зоне атаки (определенной части поля соперника, здесь нужно уточнить)
Modeled Pass Percentage Against (Will Gurpinar-Morgan)
Основываясь на этих метриках, Майкл выделил следующие группы команд для более подробного анализа (для подробных выводов нужно смотреть видео, так как презентация шла час, а учитывая акцент и скорость Майкла, пересматривать придётся не раз):
• Команды с высоким прессингом: Эйбар, Манчестер Сити (обе команды, кстати, были в топе большинства выше упомянутых метрик)
• Команды с эффективным прессингом: РБ Лейпциг, Бавария
• Команды с неэффективным прессингом: Торино, Барселона, ПСЖ
• Команды, которые в течение 2 последних сезонов претерпели тактические изменения: Челси, Тоттенхэм
• Команды со странными цифрами: Реал Мадрид, Реал Сосьедад, Бёрнли, Борнмут, Лацио, Марсель
Затем он показывал много скаттерплотов разных метрик друг против друга и пытался объяснить тенденции, но я просто не успевал записать.
Также на конференции было 2 доклада, по которым пока что неясно, поделятся ли ими с участниками конференции. Я не был на этих докладах лично, но пообщавшись через неделю с участниками конференции, а также изучив обзор Рафаэля Блая, можно сделать небольшое резюме того, что там было:
8. Adrien Tarascon: How football could revolutionize its data analysis
Презентация, позволяющая понять общее место аналитики в топовом футбольном клубе на данный момент. Главный аналитик ПСЖ рассказывал о том, как внедрить анализ данных в процессы управления клубом. По его мнению, крайне важно иметь строго определённую модель игры. Например, одним из определяющих аспектов для парижского клуба явялется способность доставлять мяч в "предпочтительные зоны навесов" (Preferred Crossing Areas) - широкие зоны внутри и поблизости вратарской.
После определения игровой модели, задаются разные ключевые показатели, отображающие эту модель, а затем опредляются более гранулярные процессы и модели, позволяющие эти показатели описать.
Ещё один важный акцент в ПСЖ делается на индивидуализацию анализа данных по каждому из игроков. Каждый игрок реагирует на указания по-разному, поэтому нужно стараться донести нюансы наилучшим способом. В качестве примера он привел Килиана Мбаппе, который не особо поглащает информацию на лекциях по теории или из отчётов, поэтому для него лучше всего на тренировках воспроизводить ситуации, с которыми он будет сталкиваться на поле. Поэтому Адриен ещё раз подчеркнул важность простоты донесения информации до игроков и тренерского штаба. Ясно, что это одна из основных проблем, с которой сталкиваются аналитики в футболе.
Также Адриен рассказал о подготовке к матчу с Реалом в рамках нынешней Лиги Чемпионов. Аналитики ПСЖ знали, что Реал - команда с высочайшим качеством переходов в атаку и навесов, поэтому они во время подготовки они показывали игрокам определённые зоны на поле, где было крайне нежелательно терять мяч. В то же время они советовали больше рисковать в тех зонах, где Реал может начать контратаку с меньшней вероятностью.
9. Vosse de Boode: "How they do it?" - technical analysis of elite skills in football
Воссе де Боде из Аякса рассказывала о научных подходах, которые использует Аякс для изучения футбола. Амстердамский клуб создал целую лабараторию для проведения различных научных экспериментов, позволяющих выявить методы улучшения обучения молодых игроков. Лаборатория фокусируется больше на игроках молодёжных команд, так как они ещё находятся в процессе обучения ввиду своего возраста.
Отличный пример работы лаборатории - изучение позиции и стойки голкипера Аякса Андре Онаны. Аналитики Аякса заметили, что нигерийский голкипер ставит ноги шире, чем это делает большинство голкиперов. Проанализировав разные данные по голкиперам, они пришли к выводу, что такая стойка более эффективна, поскольку голкипер покрывает большую часть ворот, а также может лучше прыгать. Немного неясно, работает ли данная тенденция для всех голкиперов, но в случае с Онаной подобная стойка даёт преимущество.
Также аналитики Аякса используют специальные очки для изучения фокуса зрения игроков во время игры. Недавно они выяснили, что лучшие завершители атак делают 2 взгляда: сначала смотрят на цель, потом на мяч и сразу же бьют.
Вот два видео (к сожалению, в основном на голландском), которые показывают работу лаборатории Аякса изнутри:
Также мне очень понравился последний слайд одного из докладчиков:
Понятно, что конференция была не только площадкой для презентации результатов, но также и местом, где можно было получить конструктивную критику касаемо своих исследований.
После всех презентаций было дано 2 часа на общение участников между собой, где удалось пообщаться со многими интересными людьми. Например, удалось немного поговорить с Ианом Грэхамом про его работу в Ливерпуле. Мы обсуждали вопрос донесения информации до тренеров и он привел простой пример: в своей работе Клопп очень сильно обращает внимание на общий пробег команды. В один момент сезона его команда лидировала по этому показателю по лиге, но когда через некоторое время их пробег упал, Клопп обратил на это внимание и захотел перестроить тренировочный процесс, в то время как остальные цифры были в порядке. Аналитикам Ливерпуля пришлось объяснять тренеру, что всё в порядке и что не только эта цифра является в целом определяющей.
Также удалось поговорить с человеком, который создает обучающие программы для тренеров в английской федерации футбола, и она сказала, что уже начиная с категории B, они постепенно внедряют в программу обучения тренеров базовые элементы работы с данными. Сейчас я учусь в Германии на первую тренерскую категорию C (здесь можно подробнее почитать об этом), и во время обучения мне сказали, что работа с данными начинается только после категории А.
В целом, поездка в Англию оправдала все ожидания и затраты. Судя по всему, в следующем году Statsbomb организует ешё одну, и я уверен, что туда стоит ехать, ведь не так часто удаётся встретить столько людей из индустрии в одном месте и получить столько информации. К тому же, Статсбомб дал всем участникам конференции данные по всему сезону АПЛ 2017/18. Мелочь, а очень приятно.
Если Вам понравилось, то подписывайтесь на блог и читайте его английскую версию на ksstats.com.
Фото: Gettyimages.ru/Michael Regan, Alex Livesey















Я вот тоже подумываю на категорию С пойти как доучусь, осенью 2020.
Название самого алгоритма я тупо взял со слайда, но сейчас тоже затрудняюсь найти, либо где-то отпечатался, либо там была ошибка. Кстати, уже выложили первую часть докладов: https://statsbomb.com/2019/10/statsbomb-conference-research-papers-1/ . Как выйдет вторая часть, я посмотрю статью Тома и ещё раз перепроверю.
Не удалось понять, как Т. Лоуренс использует реинфорсмет в своём исследовании? Предполагаю, что в качестве симуляции использовались данные о матчах и агент тренировался предсказывать результат (победа / поражение / ничья). Тогда отсюда и предсказание об итоговом результате, а не о следующем забитом мяче. Все равно не до конца понятно в чем профит использования реинфорсмента
Если есть вопросы - пиши!
кстати. на запрос "алгоритм NB от Google" Гугл предложил "алгоритм ИИ от Google". не уверен, что это одно и то же. или?..