Препарация статистики Ковальчука. Часть 2

Модель: Логичным продолжением предыдущей части является демонстрация и объяснение выбранной модели. Благодаря данным полученным ранее, круг сузился до полинома второй степени, вернее до предположения об адекватности упомянутой модели.
Оценка результатов: Слишком маленькая выборка, так же сама структура формирования хоккейных показателей вносят свои негативные коррективы относительно методов статистики. Невероятное кол-во внешних факторов попросту "связывают руки", к тому же полное отсутствие "места для манёвра" лишает возможности в виде подгонки моделей. Невозможно исключать негативно влияющие результаты, а так же с большой допусками применять методы тестирования и проверок. Проще говоря нельзя сказать - Илья, мне не нравится твоя статистика за прошлый сезон, величина слишком большая, поэтому я её исключаю из анализа. Но если бы структура формирования значений была иной, а счёт сезонов, например шёл на сотни, тогда такой подход имел бы смысл. Возможно, в будущем, методы будут специализированы под хоккейную статистику, но на текущий момент это лишь мечты, поэтому приходится работать с тем, что имеем. Об этих и многих других проблемах необходимо помнить при оценке результатов и "диагностике моделей", относительно хоккейной статистки, но углубляться не буду, слишком обширная тема.
R-squared - R-квадрат, он же коэффициент детерминации. Величина указывает насколько тесной является связь между факторами регрессии и зависимой переменной. Идеально около единицы.
Adjusted R-squared - Скорректированный R-квадрат. В данном случае для коррекции R-квадрат при увеличении кол-ва факторов. Добавляет своего рода "штрафы" за дополнительно включённые факторы.
Полученные значения не идеальны. Значения не являются отрицательными, поэтому говорят о том, что удалось избежать крайней неадекватности модели. Так же, даже высокие значения рассматриваются вкупе с другими результатами, к ним и перейдём.
t value и Pr(>|t|). Значения t-статистики - и критерий для него. Автоматический расчёт достаточно малого p-значения в виде "звёздочек". t value и "p", для него достаточно значимы.
F-statistic и p-value для него. Опять же не идеально, для p-value очень малые значения подтверждают истинность нулевой гипотезы. Полученное значение меньше 0,05, что является приемлемым результатом
По результатам можно говорить о неидеальной, но более-менее адекватной модели, оценка адекватности которой на совести исследователя. Не мне судить если у меня совесть, во всяком случае возьму на себя смелость использовать полученные коэффициенты для вычисления недостающего значения заброшенных шайб. Вся необходимая информация для оценки полученных результатов присутствует в прошлой части.
Публиковать продолжение о периоде выступления Ильи Ковальчука в КХЛ точно не буду. Предоставленная информация вполне достаточна для расширения кругозора и получения представлений о способах применения стат.анализа.
2. Структурируй текст, больше похоже на бессвязный поток сознания.
3. Не хочешь помимо цифр и моделей дать понятное объснение? Широкая аудитория в такое не умеет, даже с каким-то базовым набором знаний пришлось сидеть и долго разбираться что ты хотел показать. А так больше похоже на "я тут посчитал, разбирайтесь". Неувожение, однако.
4. Я так и не понял чем твои выкладки лучше того же Corsi, сорян.
Как только была сформулирована проблема, сразу же исправил.
"2. Структурируй текст, больше похоже на бессвязный поток сознания. "
Опубликован микс из самой разнообразной информации, по сути выжимка из попыток применения различных методов. В виду полного отсутствия стандартов и сложившихся методов, а так же отсутствия самой структуры, лучше форматировать не получится. К тому же, делаю не для презентации, а для себя.
"3. дать понятное объснение?"
Оно присутствует и более чем достаточное. Саму теорию объяснять нет смысла, придётся писать невероятное кол-во информации, причём понятней ничего не станет. Писательского таланта у меня нет, сам предпочитаю больше читать, чем писать.. Одна из надежд была в том, что кто-нибудь прочитает и в дальнейшем сделает намного лучше. Когда более компетентный делится с остальными, берут в предоставленной форме или проходят мимо. Дарёному коню..
"4. Я так и не понял чем твои выкладки лучше того же Corsi, сорян."
Не лучше и не хуже Corsi. Не понятно к чему упоминание. Достаточно интересный абсолютный(CF) и относительный показатель(CF%). Другое дело, что среди болельщиков выполняет роль развлекательной нумерологии с соответствующими выводами, не более.
Если владеете инглишем, почитайте западные блоги о продвинутой стате, поможет в развитии. Успехов
Не за что. Пока что идёт этап осмысления, это всё пробы пера.
"какие программы использовал для своих подсчётов?"
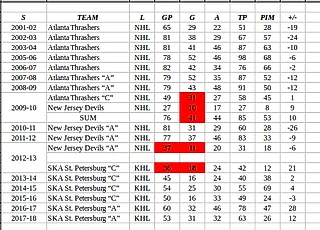
Программы лишь способ автоматизации, они бесполезны на первых этапах. Почти всё делал вручную, потом в офисе выводил, потом стандартными стат.функциями офиса. И даже для этого необходимо понимать, что делаешь. На первом скрине R, python конкурирует с ним на равных.
Вопрос был чисто технический, а за ответ ещё одна благодарность
Советую публикануться ещё на Хабре с более подробным описанием процесса с точки зрения разработки и математики. Однозначно мог бы получиться неплохой tutorial.